1.1 Ferramentas
The process of preparing programs for a digital computer is especially attractive because it not only can be economically and scientifically rewarding, it can also be an aesthetic experience much like composing poetry or music. (Knuth 1968, v)
1.1.1 R
R é uma ferramenta para cálculos estatísticos e gráficos. Foi desenvolvida no Departamento de Estatística da Universidade de Auckland, e seu código está disponível sob a licença GNU (GNU is Not Unix) GPL4. Atualmente a R Foundation está sediada na Universidade de Economia e Negócios de Viena, Áustria. Foi influenciado por linguagens como S e Scheme seguindo um paradigma minimalista orientado a objeto, que especifica um pequeno núcleo padrão acompanhado de pacotes para a extensão da linguagem. Na data de fechamento deste material em 2026-05-19 havia 23696 pacotes oficiais disponíveis, incluindo o pacote voice do autor.
R é uma linguagem interpretada, o que significa que ela compila cada linha de comando, interativamente, conforme ela é fornecida. Isso torna o R excelente para explorar dados e implementar soluções, mas esta mesma qualidade o torna mais lento para grandes conjuntos de dados e para programas que envolvem muitas etapas. Para computação desse tipo, os programas são comumente escritos e executados em C ou C++, mas isso não precisa ser uma preocupação agora: o refinamento das habilidades necessárias para otimizar códigos complexos é obtido com a prática.

Recomenda-se atualizar o R e seus pacotes a cada ciclo de trabalho. No Windows recomenda-se ainda a instalação do Rtools de acordo com a versão instalada do R. Os pacotes utilizados neste curso podem ser instalados e atualizados conforme código abaixo. No caso de utilização de sistema operacional do tipo Unix, recomenda-se rodar as instruções acima em um terminal após executar o comando sudo R seguido da senha do sistema. Nos sistemas macOS pode ser necessária a instalação de alguns componentes adicionais disponíveis em macOS Tools.
# pacotes a serem instalados no Linux (Debian, Ubuntu)
sudo apt-get install libfreetype6-dev libpng-dev libtiff5-dev \
libjpeg-dev libharfbuzz-dev libfribidi-dev libfontconfig1-dev \
libxml2-dev libcurl4-openssl-dev libmagick++-dev libgmp3-dev \
libgsl-dev glpk-utils libglpk-dev libgit2-dev cmake cargo \
libpoppler-cpp-dev libtesseract-dev tesseract-ocr-eng \
libleptonica-dev libavilter-dev libfftw3-dev libiodbc2-dev \
unixodbc unixodbc-dev
sudo apt autoremove# pacotes adicionais utilizados no curso
chooseCRANmirror(ind = 11) # https://cran.fiocruz.br
install.packages('arrangements', dep = TRUE)
install.packages('basedosdados', dep = TRUE)
install.packages('BFpack', dep = TRUE)
install.packages('bookdown', dep = TRUE)
install.packages('bootstrap', dep = TRUE)
install.packages('chisq.posthoc.test', dep = TRUE)
install.packages('coronavirus', dep = TRUE)
install.packages('DescTools', dep = TRUE)
install.packages('devtools', dep = TRUE)
install.packages('DT', dep = TRUE)
install.packages('edfReader', dep = TRUE)
install.packages('EnvStats', dep = TRUE)
install.packages('factoextra', dep = TRUE)
install.packages('fbst', dep = TRUE)
install.packages('FSA', dep = TRUE)
install.packages('HDInterval', dep = TRUE)
install.packages('hdrcde', dep = TRUE)
install.packages('HistData', dep = TRUE)
install.packages('klaR', dep = TRUE)
install.packages('LearnBayes', dep = TRUE)
install.packages('magick', dep = TRUE)
install.packages('markovchain', dep = TRUE)
install.packages('performance', dep = TRUE)
install.packages('philentropy', dep = TRUE)
install.packages('pracma', dep = TRUE)
install.packages('rgl', dep = TRUE)
install.packages('rje', dep = TRUE)
install.packages('sampling', dep = TRUE)
install.packages('SHELF', dep = TRUE)
install.packages('skimr', dep = TRUE)
install.packages('sos', dep = TRUE)
install.packages('symmetry', dep = TRUE)
install.packages('tidyverse', dep = TRUE)
install.packages('unitquantreg', dep = TRUE)
install.packages('VGAM', dep = TRUE)
install.packages('VIM', dep = TRUE)
install.packages('XML', dep = TRUE)
pak::pak('filipezabala/desempateTecnico')
pak::pak('filipezabala/jurimetrics')
pak::pak('filipezabala/voice')
pak::pak('kassambara/ggcorrplot')
pak::pak('stefano-meschiari/latex2exp')
pak::pak('gadenbuie/tweetrmd')
pak::pak('rstudio/webshot2')
update.packages(ask = FALSE) # atualizar a cada ciclo de trabalhoCaso a instalação de um ou mais pacotes retorne uma mensagem de non-zero exit status, tente rodar novamente a instalação. Caso o problema persista, leia atentamente às mensagens apresentadas durante a execução, que indicam o que pode estar faltando. Copiar e colar as mensagens de erro no Google é um passo importante, pois há fóruns técnicos como o Stackoverflow que fornecem ótimas sugestões de solução.
1.1.1.2 RStudio
RStudio é um ambiente de desenvolvimento integrado (IDE) para R e Python. Possibilita a criação de apresentações e relatórios automáticos em diversos formatos como pdf, html e docx, mesclando linguagens como R, Python, LaTeX, markdown, C, C++, SQL, HTML, CSS, JavaScript, Stan e D3. Ocupa cerca de 740MB em disco, e está disponível nas edições Desktop e Server, reunindo as funcionalidades do R de forma parcimoniosa.
![]()
1.1.1.3 R online
- https://colab.research.google.com/#create=true&language=r (Versão 4.5.2)
- https://webr.r-wasm.org/latest/ (Versão 4.5.1, Documentação)
- https://www.jdoodle.com/execute-r-online (Versão 4.3.2)
- https://www.programiz.com/r/online-compiler (Versão 4.2.3)
- https://jupyter.org/try (Versão 4.1.3, escolha a aba ‘R’)
- https://www.mycompiler.io/new/r (Versão 4.1.2)
- https://rdrr.io/snippets (Versão 4.0.3)
- https://filipezabala.com/r (Versão 3.4.0)
1.1.1.4 CRAN Task Views
As CRAN Task Views visam fornecer informações sobre os pacotes da CRAN (Comprehensive R Archive Network) relacionados a um determinado tópico. É recomendado verificar os assuntos de interesse nas CRAN Task Views para uma abordagem mais completa utilizando a linguagem R.
1.1.2 Python
Python é uma linguagem de programação interpretada, interativa e orientada a objetos. Ela incorpora módulos, exceções, classes, tipagem dinâmica e tipos de dados dinâmicos de nível muito alto. Oferece suporte a vários paradigmas de programação além da programação orientada a objetos, como a programação procedural e funcional. Possui interfaces para muitas chamadas de sistema e bibliotecas, bem como para vários sistemas de janela, sendo extensível em C ou C ++. Pode também ser usada como uma linguagem de extensão para aplicativos que precisam de uma interface programável. Finalmente, o Python é portátil: roda em muitas variantes do Unix, incluindo Linux e macOS, e no Windows.
Os códigos Python deste material foram gerados e adaptados a partir dos códigos originais em R via Gemni Advanced 2.0 Flash (AI 2023) e DeepSeek-V3 (DeepSeek 2023). Após testar, sinta-se à vontade para colaborar com sugestões e, de preferência, melhorias dos códigos. De acordo com o Gemni, a média da relação entre o número de linhas de código Python e R foi de 2.45, i.e., o código Python apresentou, em média, 2.45 vezes o número de linhas do código R original (excluindo linhas em branco e comentários). Quando considerados os caracteres, a média foi de 1.86, ou seja, o código Python neste material é 86% maior em número de caracteres.
![]()
1.1.2.1 Pedindo ajuda
Para mais informações veja https://docs.python.org/.
1.1.2.2 SymPy
SymPy é uma biblioteca Python para matemática simbólica. De acordo com a documentação, o objetivo é se tornar um sistema de álgebra computacional (CAS) completo, mantendo o código o mais simples possível para ser compreensível e facilmente extensível.
SymPy Gamma é uma aplicação web baseada no Google App Engine que executa e exibe os resultados de expressões SymPy, bem como cálculos adicionais relacionados, de maneira semelhante ao Wolfram|Alpha.
1.1.2.3 Python em R Markdown
O pacote reticulate (Ushey et al. 2024) inclui um mecanismo Python para R Markdown que executa trechos de Python em uma única sessão Python incorporada em sua sessão R, permitindo o acesso a objetos criados em trechos de Python do R e vice-versa.
Exercício 1.2 Ler a documentação do reticulate disponível em https://rstudio.github.io/reticulate/.

1.1.3 Jupyter
Jupyter é uma plataforma que utiliza padrões abertos e serviços da Web para computação interativa em uma infinidade de linguagens de programação. Há diversos aplicativos disponíveis neste link, que permitem executar linguagens variadas em um ambiente dinâmico e personalizável.
![]()
1.1.3.1 Google Colab
Colab é um produto do Google Research. O Colab permite a escrita e execução de código Python por meio do navegador. É um serviço de notebook Jupyter pré configurado que fornece acesso a recursos computacionais, incluindo GPUs.
![]()
1.1.4 Stan
Stan é uma plataforma de código aberto para modelagem e computação estatística de alto desempenho. É uma homenagem ao matemático e físico Stanislaw Ulam, um dos autores do Método de Monte Carlo. É também utilizado para análise de dados e previsão nas ciências sociais, biológicas e físicas, engenharia e negócios. A biblioteca de matemática de Stan fornece funções de probabilidade e álgebra linear. Pacotes de R adicionais fornecem modelagem linear baseada em expressão, visualização da posteriori e validação cruzada de exclusão. Existem interfaces para diversos ambientes de computação populares, tais como RStan (R), PyStan (Python), Stan.jl (Julia) entre outras. Usando a linguagem pode-se obter:
- Inferência estatística bayesiana completa com amostragem MCMC (NUTS, HMC)
- Inferência bayesiana aproximada com inferência variacional (ADVI)
- Estimativa de máxima verossimilhança penalizada com otimização (L-BFGS)
![]()
1.1.5 JASP
JASP (Jeffreys’s Amazing Statistics Program) é um projeto de código aberto apoiado pela Universidade de Amsterdã. Com interface amigável, oferece procedimentos de análises estatísticas com abordagens clássica e bayesiana. Ocupa cerca de 1.1GB em disco, e foi desenvolvido para análises de publicação. Dentre suas principais características, estão
- Atualização dinâmica de todos os resultados
- Layout de planilha e uma interface de arrastar e soltar
- Saída anotada para comunicar seus resultados
- Integração com o Open Science Framework (OSF)
- Suporte para formato APA (copie gráficos e tabelas diretamente no Word)
![]()
1.1.7 JAMOVI
JAMOVI é um projeto de código aberto indicado como uma “planilha estatística de 3ª geração”. A proposta é ser uma alternativa para produtos estatísticos caros, como SPSS e SAS, fornecendo acesso aos últimos desenvolvimentos da metodologia estatística. Possui integração com a linguagem estatística R, e o acesso pode ser feito remotamente ou via desktop.
![]()
1.1.8 PSPP
PSPP é um programa para análise estatística de dados. Interpreta comandos na linguagem SPSS e produz saída tabular em formato ASCII, PostScript ou HTML. Permite realizar estatísticas descritivas, testes t, ANOVA, regressão linear e logística, medidas de associação, análise de cluster, confiabilidade e análise fatorial, testes não paramétricos, dentre outras análises. Ocupa cerca de 160MB em disco, e pode ser utilizado com a interface gráfica ou os sintaxe via linha de comando. Uma breve lista de alguns dos recursos do PSPP segue abaixo:
- Suporte para mais de 1 bilhão de casos (linhas)
- Suporte para mais de 1 bilhão de variáveis (colunas)
- Arquivos de sintaxe e dados compatíveis com os do SPSS
- Uma escolha de terminal ou interface gráfica do usuário
- Uma escolha de formatos de saída de texto, postscript, pdf, opendocument ou html
- Interoperabilidade com Gnumeric, LibreOffice e outros softwares livres
- Fácil importação de dados de planilhas, arquivos de texto e fontes de banco de dados
- A capacidade de abrir, analisar e editar dois ou mais conjuntos de dados simultaneamente. Eles também podem ser mesclados, unidos ou concatenados
- Uma interface de usuário que suporta todos os conjuntos de caracteres comuns e que foi traduzida para vários idiomas
- Procedimentos estatísticos rápidos, mesmo em conjuntos de dados muito grandes
- Sem taxas de licença ou período de expiração
- Portabilidade: funciona em computadores e sistemas operacionais diferentes

1.1.9 LibreOffice Calc
LibreOffice é um pacote de escritório livre e sucessor do OpenOffice.org. Inclui vários aplicativos, dos quais destaca-se o programa de planilhas Calc. Possui as seguintes funcionalidades:
- Funções, que podem ser usadas para criar fórmulas para realizar cálculos complexos em dados
- Funções de banco de dados para organizar, armazenar e filtrar dados
- Ferramentas de estatísticas, para realizar análises complexas de dados
- Gráficos dinâmicos, incluindo uma ampla gama de gráficos 2D e 3D
- Macros para registro e execução de tarefas repetitivas; linguagens de script suportadas incluem LibreOffice Basic, Python, BeanShell e JavaScript
- Capacidade de abrir, editar e salvar planilhas do Microsoft Excel
- Importar e exportar planilhas em vários formatos, incluindo HTML (HyperText Markup Language), CSV (Comma Separated Value(s)), PDF (Portable Document Format) e DIF (Data Interchange Format)
![]()
1.1.10 Kedro
Kedro é um framework Python de código aberto hospedado pela Linux Foundation (LF AI & Data).
1.1.11 EDF Browser
EDF Browser é um visualizador, anotador e caixa de ferramentas universal, multiplataforma, gratuito e de código aberto, destinado a, mas não limitado a, arquivos de armazenamento de séries temporais como EEG, EMG, ECG e BioImpedance.
Vis (2019) lê arquivos EDF (European Data Format) e EDF+ no R. Veja a vinheta.
Gramfort et al. (2013) apresenta MNE, um pacote Python de código aberto para explorar, visualizar e analisar dados neurofisiológicos humanos como MEG, EEG, sEEG, ECoG e NIRS. Destaque para a função mne.io.read_raw_edf(), que lê arquivos EDF and EDF+.
Mais informações
1.1.12 Tabula
Tabula é uma ferramenta para liberar tabelas de dados trancadas em arquivos PDF. De acordo com a documentação será sempre gratuita e de código aberto.
- Funciona em Mac, Windows e Linux
- Permite extrair dados em uma planilha CSV ou Microsoft Excel usando uma interface simples
- Funciona apenas em PDFs baseados em texto, não em documentos digitalizados
- Todo o processamento ocorre em máquina local
- Usado para impulsionar reportagens investigativas em organizações de notícias de todos os tamanhos, incluindo ProPublica, The Times of London, Foreign Policy e La Nación
- Pesquisadores de todos os tipos usam o Tabula para transformar relatórios PDF em planilhas do Excel, CSVs e arquivos JSON para uso em aplicativos de análise e banco de dados

1.1.14 Nomogramas
d’Ocagne (1899) é considerado um marco no estudo da nomografia. Em sua segunda edição, d’Ocagne (1921), p. v define6 o tema como “o estudo geral da representação gráfica com dimensões de equações com \(n\) variáveis, com vista à construção de tabelas gráficas que traduzam as leis (\(\eta\)ó\(\mu\)o\(\varsigma\)) matemáticas das quais estas equações constituem a expressão analítica. Estas tabelas, denominadas nomogramas, permitem, por meio de uma simples leitura, guiada pela observação imediata de uma certa relação de posição entre elementos geométricos dimensionados, ter o valor de uma destas \(n\) variáveis que corresponde a um sistema de valores dado pelas outras \(n-1\)”.
Khovanskii (1979) (p. 7) aponta7 que “qualquer nomograma é composto de elementos simples: escalas, campos binários, famílias de linhas, linhas e pontos. As escalas são encontradas em decímetros duplos, termômetros, em vários aparelhos físicos. Um exemplo típico de um campo binário é a rede de paralelos e meridianos de mapas geográficos.”
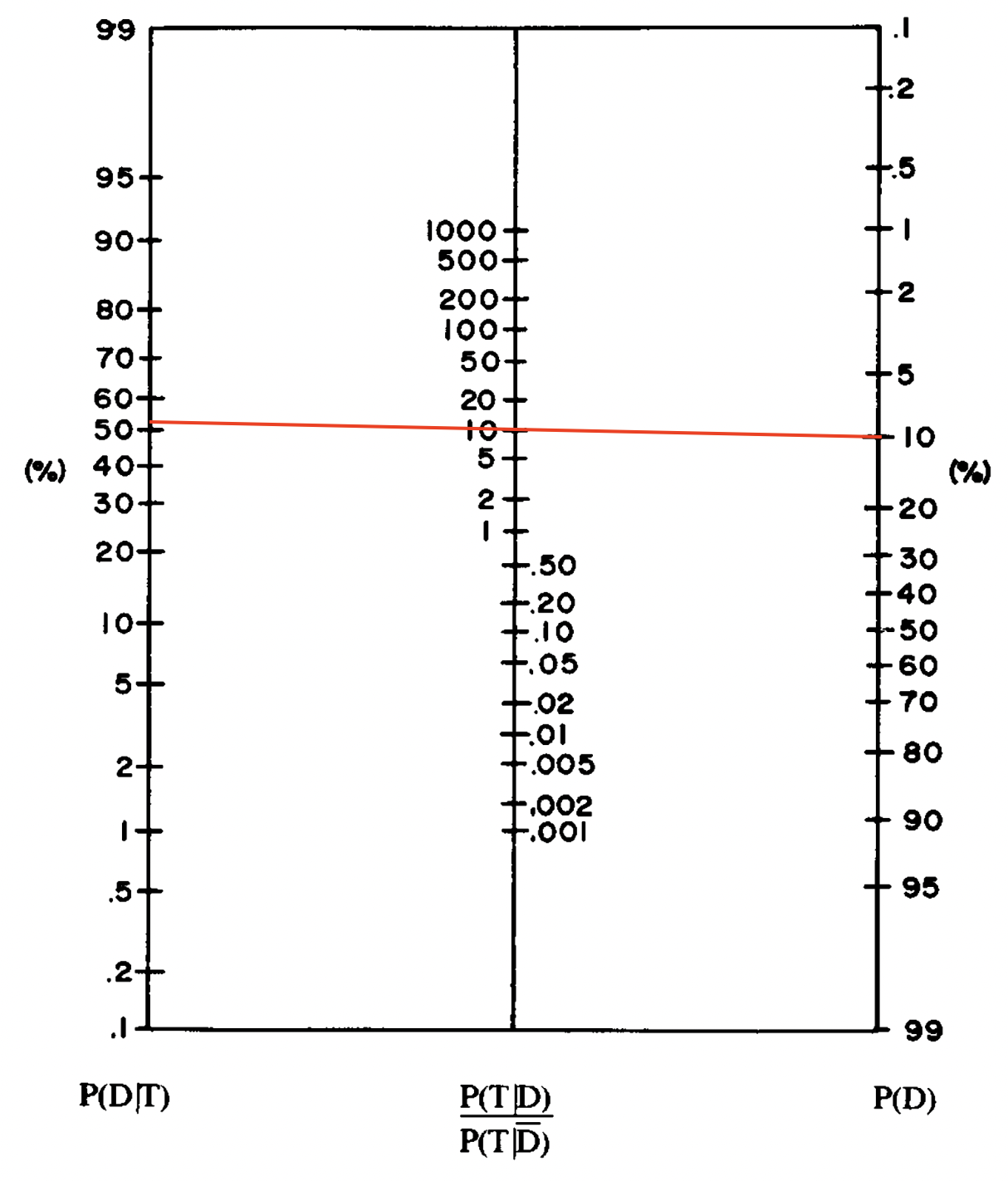
Exemplo 1.1 A régua de cálculo Pickett N525-ES StatRule Slide Rule é um exemplo da aplicação dos métodos de nomografia para cálculos estatísticos. Pode ser encontrada em http://solo.dc3.com/VirtRule/n525es/virtual-n525-es.html.
Exemplo 1.2 (Fagan 1975) apresenta uma solução para a regra de Bayes envolvendo
- \(P(D)\), a probabilidade de o paciente ter a doença antes do teste
- \(P(D|T)\), a probabilidade de o paciente ter a doença depois do resultado positivo do teste
- \(P(T|D)\), a probabilidade de resultado positivo no teste se o paciente tem a doença
- \(P(T|\bar{D})\), a probabilidade de resultado positivo no teste se o paciente não tem a doença
Se \(P(T|D)=100\%\) e \(P(T|\bar{D})=10\%\), então \(\frac{P(T|D)}{P(T|\bar{D})}=10\). Para \(P(D) = 10\%\), uma linha traçada entre esses valores devolve algo próximo de \(P(D|T)=53\%\).
References
A Licença Pública Geral GNU é um tipo de licença utilizada para software livre, que garante aos usuários finais (indivíduos, organizações ou empresas) a liberdade de usar, estudar, compartilhar e modificar o software.↩︎
Programação probabilística é um paradigma de programação no qual modelos probabilísticos são definidos e a inferência destes modelos é feita automaticamente, usualmente utilizando métodos numéricos.↩︎
La Nomographie a pour objet l’étude générale de la représentation graphique cotée des équations à n variables, en vue de la construction de tables graphiques traduisant les lois (vóuas) mathématiques dont ces équations constituent l’expression analytique. Ces tables, dites nomogrammes, permettent, au moyen d’une simple lecture, guidée par la constatation immédiate d’une certaine relation de position entre éléments géométriques cotés, d’avoir la valeur d’une de ces n variables qui correspond à un système de valeurs données pour les n-1 autres.↩︎
Tout abaque est constitué d’éléments simples : échelles, champs binaires, familles de lignes, lignes et points. On rencontre les échelles sur les doubles-décimètres, les thermomètres, dans divers appareils de physique. Un exemple type de champ binaire est le réseau de parallèles et de méridiens des cartes de géographie.↩︎