2.6 Visualização
A graph is a set of points. A mathematical graph cannot be seen. It is an abstraction. A graphic, however, is a physical representation of a graph. This representation is accomplished by realizing graphs with aesthetic attributes such as size or color. (Wilkinson 2005, 6)
Visualização é o processo de representar informações ou ideias através de diagramas, gráficos estatísticos15 e outros métodos de apresentação visual. De um modo geral, as ferramentas de visualização devem ser claras para o leitor, devendo-se evitar detalhes desnecessários. Um bom visualizador transmite a informação desejada de forma clara, precisa e eficiente.
De acordo com (Kopf 1916), além de “quarenta anos de pensamento e realização na questão indiana” (Walker 1874), “salvaguardando a saúde do soldado britânico”, “reorganizando a administração hospitalar civil e militar no país e no exterior” e “seus serviços pioneiros para a profissão de enfermagem”, as atividades de Florence Nightingale na Estatística “podem ser classificadas em várias categorias amplas”. “A Dama com a Lâmpada”, uma “estatística apaixonada” de acordo com (Cook 1913), popularizou o diagrama de área polar, o que ela chamou de “coxcombs” (Cohen 1984). Além disso, fez um excelente trabalho na parte de visualização na documentação de informações relacionadas às frentes de guerra (Nightingale 1858).
Edward Tufte, “o Leonardo da Vinci dos dados” segundo The New York Times, ou “o Galileu dos gráficos” de acordo com a Bloomberg, possui uma vasta obra sobre o tema, destacando-se (Tufte 1993), (Tufte et al. 1998), (Tufte and Graves-Morris 2001), (Tufte 2006) e (Tufte 2020). Mais recentemente encontram-se artistas visuais como Karim Douieb16, que possui um considerável portfolio publicado.
Baseado em (Tufte 1983), (Tufte 1993) e (Cleveland 1985), (Cleveland 1993), Rob Hyndman sugere 20 regras para bons gráficos.
- Use gráficos vetoriais como eps ou pdf.
- Use fontes legíveis.
- Evite legendas desorganizadas.
- Se você precisar usar uma legenda, mova-a para dentro do gráfico.
- Não use fundos escuros sombreados.
- Evite linhas de grade escuras e dominantes.
- Mantenha os limites dos eixos sensatos.
- Não se esqueça de especificar as unidades.
- Os intervalos de escala devem estar em números redondos e agradáveis.
- Os eixos devem ser rotulados corretamente.
- Use larguras de linha grandes o suficiente para leitura.
- Evite sobreposição de texto em caracteres ou linhas de plotagem.
- Siga os princípios de Tufte removendo lixo de gráficos e mantendo uma alta proporção de dados-tinta.
- Os gráficos devem ser autoexplicativos.
- Use uma proporção de tela sensata.
- Use pontos, não linhas, se a ordem dos elementos não for relevante.
- Use linhas se a ordem dos elementos for relevante (por exemplo, tempo).
- Use escalas comuns para comparação (ou um único gráfico).
- Evite gráficos de pizza. Especialmente gráficos de pizza 3D. Especialmente gráficos de pizza 3D com fatias explosivas.
- Nunca use padrões de preenchimento como hachuras cruzadas.
2.6.1 Exemplos
Exemplo 2.99 Visualização considerando os princípios indicados.

by Max Roser at ourworldindata.org/longtermism
It is these 109 billion people we have to thank for the civilization that we live in. The languages we speak, the food we cook, the music we enjoy, the tools we use – what we know we learned from them. Max Roser (2022-03-15)
Exemplo 2.100 Terra não vota. Pessoas votam.17
I have the feeling my map is becoming for the US elections what's the @MariahCarey's song "All I want for Christmas is you" has become for the holiday season... https://t.co/5Z2VrsgdTA
— Karim Douïeb (@karim_douieb) November 12, 2022
Exemplo 2.101 Bicicleta seria o transporte do futuro inventado no passado?18
Works in Rotterdam too :) pic.twitter.com/UFbOxEx4Yb
— Wouter Stern (@Twouttter) March 15, 2023
Exemplo 2.102 De acordo com (Zabala 2009), se há três candidatos na iminência do empate técnico conforme o método adotado pelos institutos de pesquisa – i.e., \(A\) empata com \(B\) por um ponto, \(B\) empata com \(C\) por um ponto mas \(A\) e \(C\) não empatam (??) –, a elipse azul no simplex abaixo indica os prováveis cenários eleitorais com uma amostra de tamanho 500. No caso, deve haver segundo turno entre \(A\) e \(B\).
if(type_book == 'bookdown::gitbook'){
desempateTecnico::simplex3d(.3919345050, .3324785813, .2755869137, 500)
rgl::rglwidget()
}
2.6.2 Gráficos básicos
2.6.2.1 Pizza/Setores
O princípio do gráfico de setores, o popular gráfico de pizza, é desenhar setores/fatias proporcionais às frequências das categorias. Seguindo a etiqueta da apresentação gráfica, recomenda-se a utilização deste tipo de gráfico para, no máximo, dez categorias. Por padrão os setores são apresentados em sentido anti-horário iniciando em 0º.
| País | Associação |
|---|---|
| Brasil, Finlândia | Pizza |
| EUA, UK, Alemanha, Croácia, Suécia | Torta/bolo |
| França | Queijo camembert |
Exemplo 2.103 Em R.
atend <- c(90,62,31,44,13) # Número de atendimentos
colors <- gray(0:4/4) # Cinco tons de cinza
atend_rel <- round(atend/sum(atend) * 100, 1) # Calculando percentuais
atend_rel <- paste(atend_rel, '%', sep='') # Adicionando '%'
# Frequência (da classe)
pie(atend, main = 'Atendimentos', col = colors, labels = atend)
legend(1.1, 0.9, c('Seg','Ter','Qua','Qui','Sex'),
fill = colors, box.col = 'white')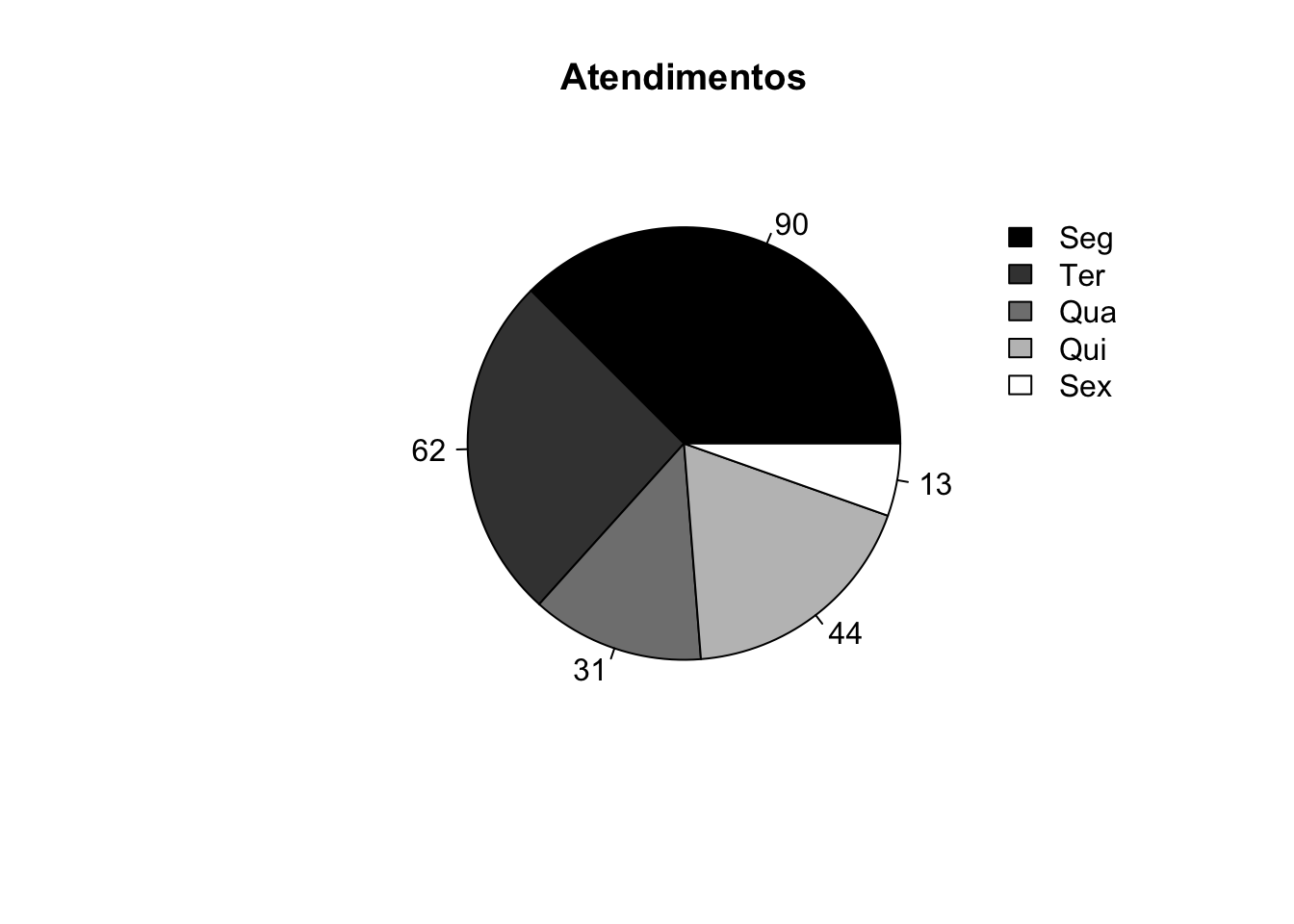
# Frequência relativa
pie(atend, main = 'Atendimentos', col = colors, labels = atend_rel)
legend(1.3, 0.9, c('Seg','Ter','Qua','Qui','Sex'),
fill = colors, box.col='white')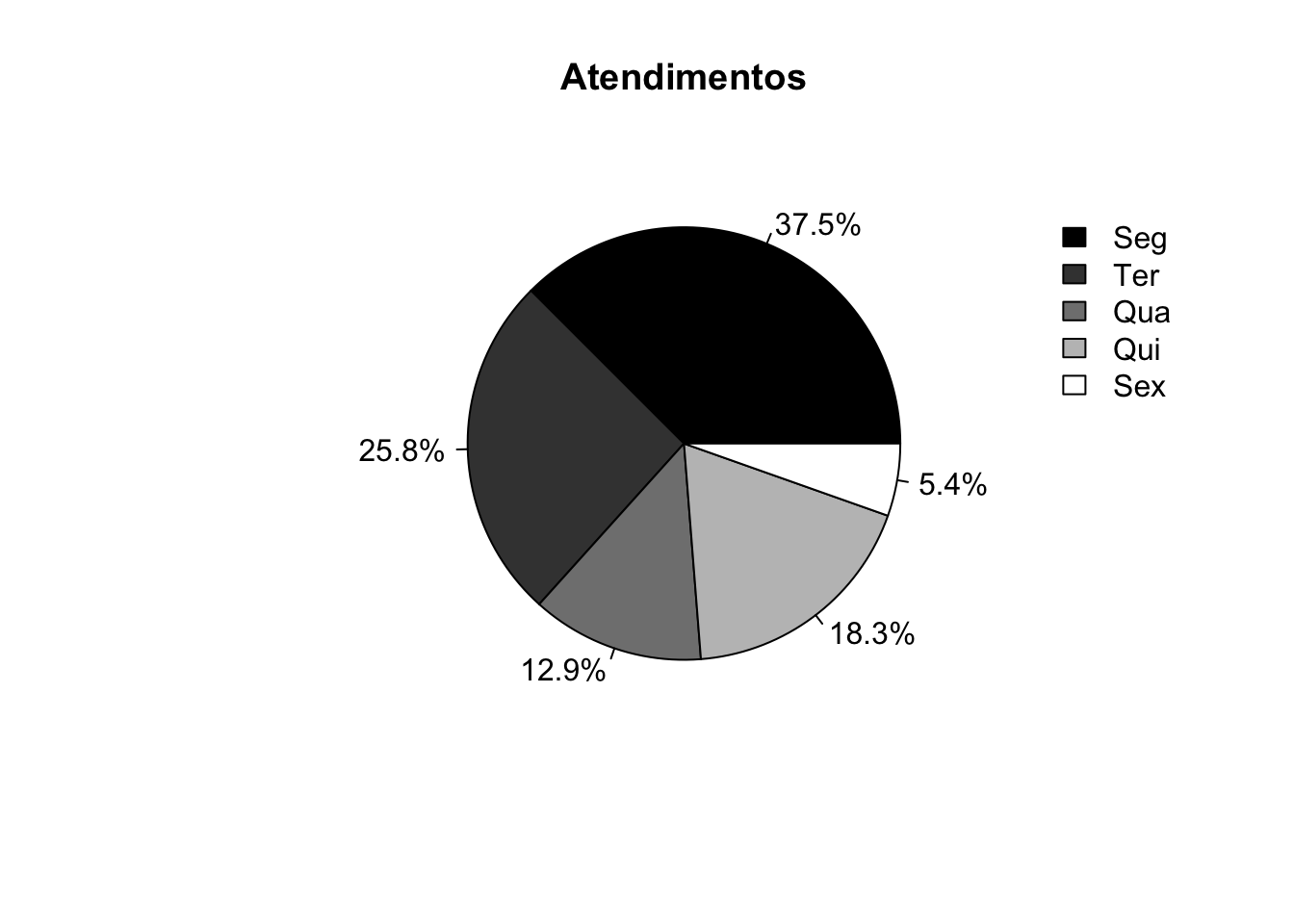
Exemplo 2.104 Em Python.
import matplotlib.pyplot as plt
import numpy as np
# Dados
atend = np.array([90, 62, 31, 44, 13])
dias_semana = ['Seg', 'Ter', 'Qua', 'Qui', 'Sex']
# Calculando os percentuais
atend_rel = np.round(atend / np.sum(atend) * 100, 1)
# Adicionando o símbolo de porcentagem
labels_rel = [f'{p}%' for p in atend_rel]
# Criando os gráficos de pizza
fig, axs = plt.subplots(1, 2, figsize=(12, 6))
# Gráfico de pizza com frequência absoluta
axs[0].pie(atend, labels=atend, colors=plt.cm.gray(np.arange(5)/4),
autopct='%1.1f%%', startangle=140)
axs[0].set_title('Atendimentos', fontsize=16)
axs[0].legend(dias_semana, loc="best")
# Gráfico de pizza com frequência relativa
axs[1].pie(atend, labels=labels_rel, colors=plt.cm.gray(np.arange(5)/4),
autopct='%1.1f%%', startangle=140)
axs[1].set_title('Atendimentos', fontsize=16)
axs[1].legend(dias_semana, loc="best")
plt.show()2.6.2.2 Barras e Colunas
O gráfico de barras é usualmente utilizado para apresentar dados classificados em categorias não ordenadas. Barras retangulares de mesma largura são dispostas sobre as categorias com altura proporcional às frequências ou outra medida associada com as categorias. Podem ser dispostas na horizontal ou vertical; quando agrupadas desta última forma, chama-se gráfico de colunas. É um gráfico bastante versátil, pois permite representar a informação de diversas maneiras.
Exemplo 2.105 Em R.
# Dados
custos <- c(760, 640, 75, 850, 100)
names(custos) <- LETTERS[1:5]
# Barras
barplot(custos, xlab = 'Custo (R$)', main = 'Custos pessoais',
col = gray(0:4/4), las = 1, cex.main = 1.6, horiz = TRUE)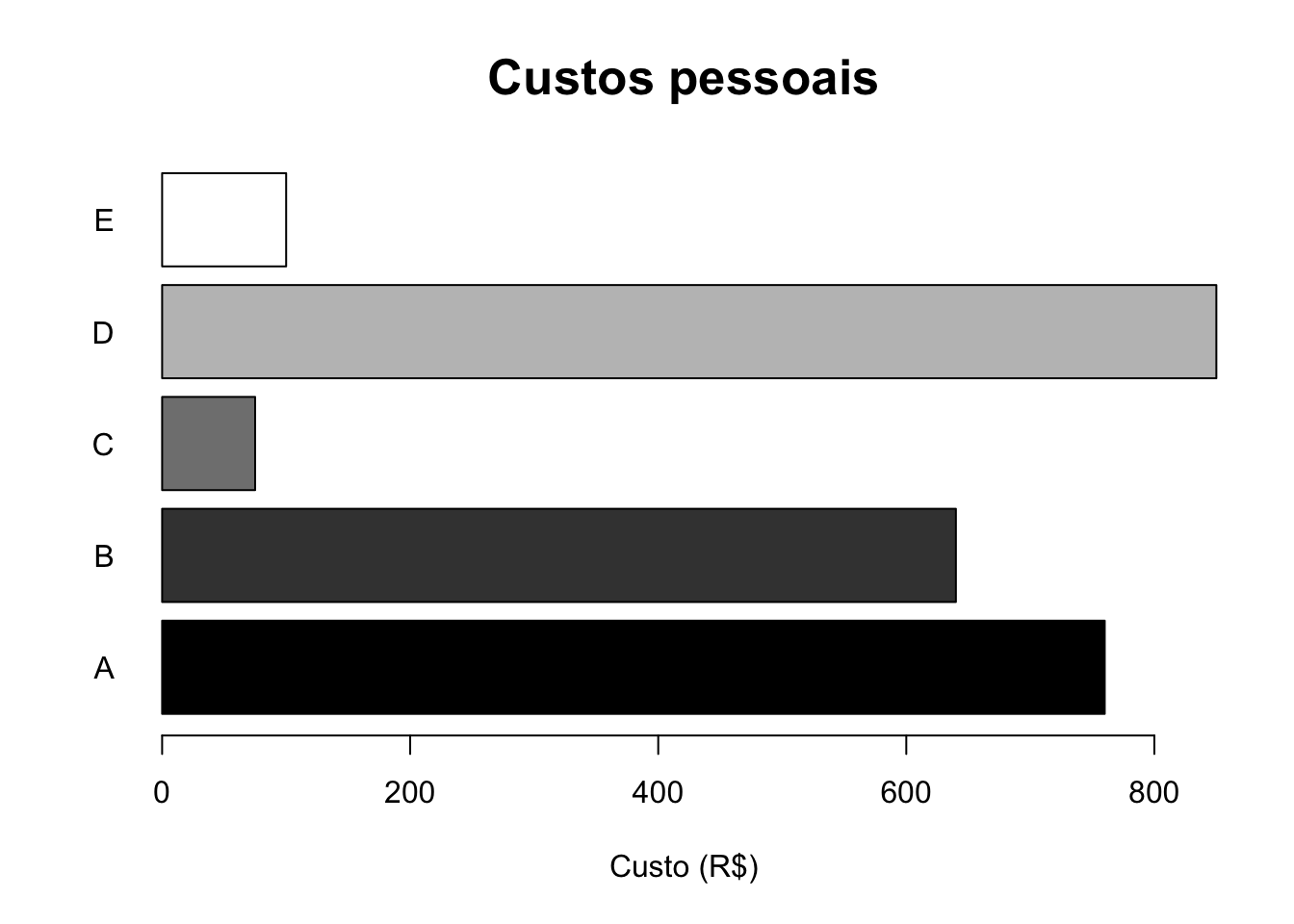
# Colunas
barplot(custos, ylab = 'Custo (R$)', main = 'Custos pessoais',
col = gray(0:4/4), las = 0, cex.main = 1.6)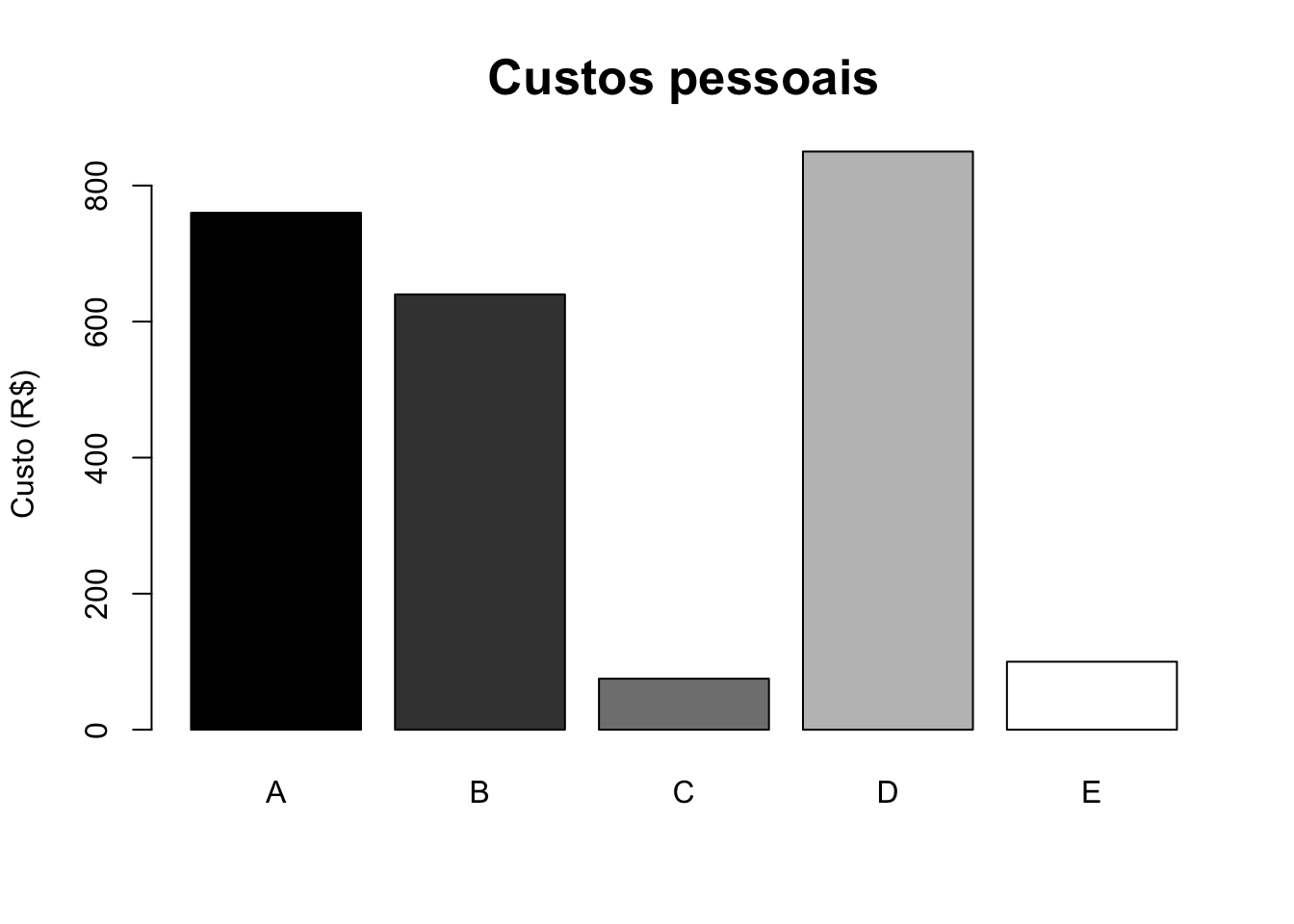
# Colunas empilhadas
library(vcd)
trat <- table(Arthritis$Improved, Arthritis$Treatment)
rownames(trat) <- c('Nenhuma melhora','Alguma melhora',
'Plena melhora')
colnames(trat) <- c('Placebo', 'Tratamento')
barplot(trat,
main = 'Placebo vs tratamento',
ylab = 'Frequência',
col = c('black', 'grey', 'white'),
cex.main = 1.6)
legend(1.5, 40, rownames(trat), cex = 1, fill = colors[c(1,3,5)],
box.col = 'white')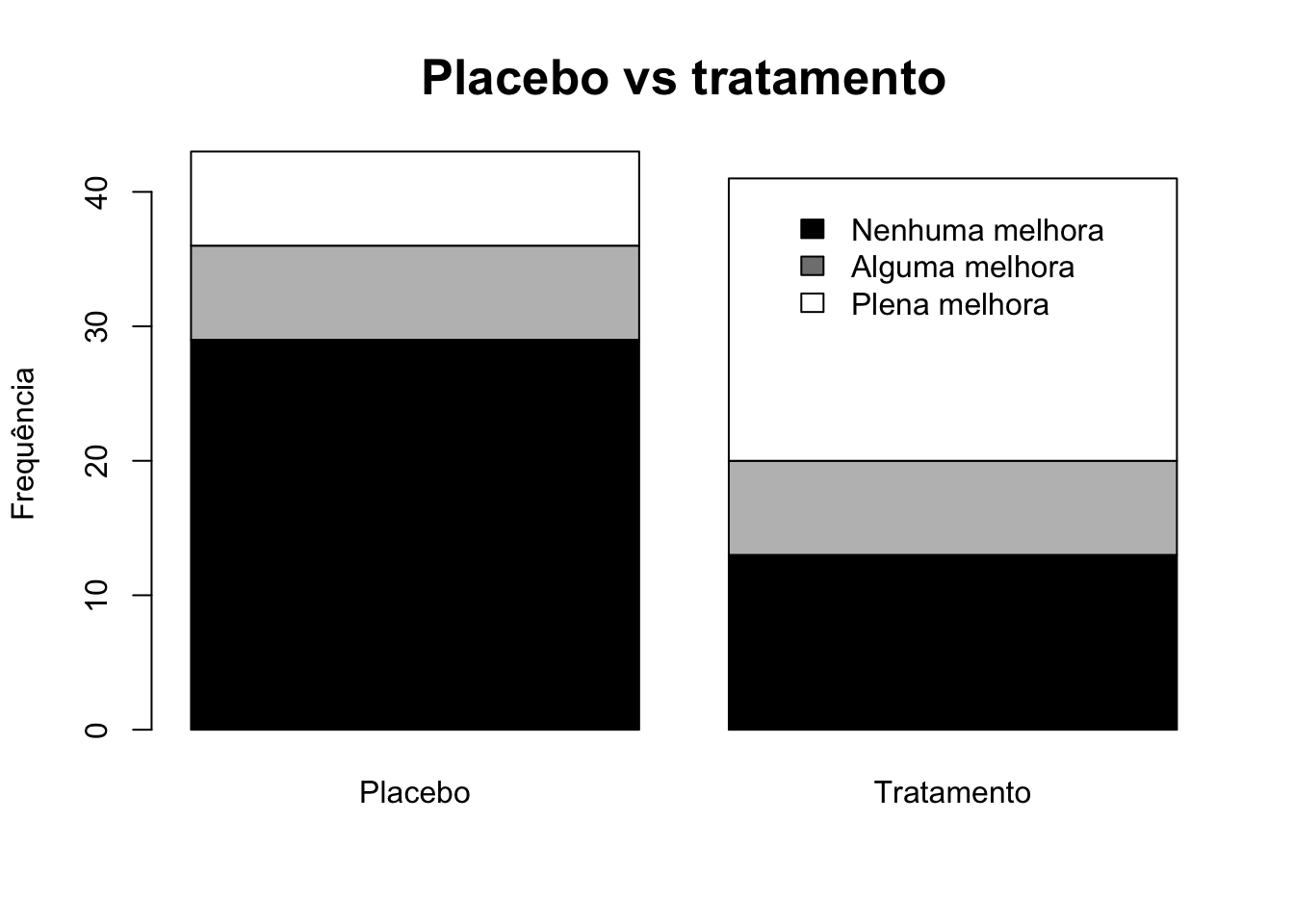
# Colunas lado a lado
barplot(trat,
main = 'Placebo vs tratamento',
ylab = 'Frequência',
col = c('black', 'grey', 'white'),
cex.main = 1.6, beside = TRUE)
legend(4, 28, rownames(trat), cex = 1, fill = colors[c(1,3,5)],
box.col = 'white')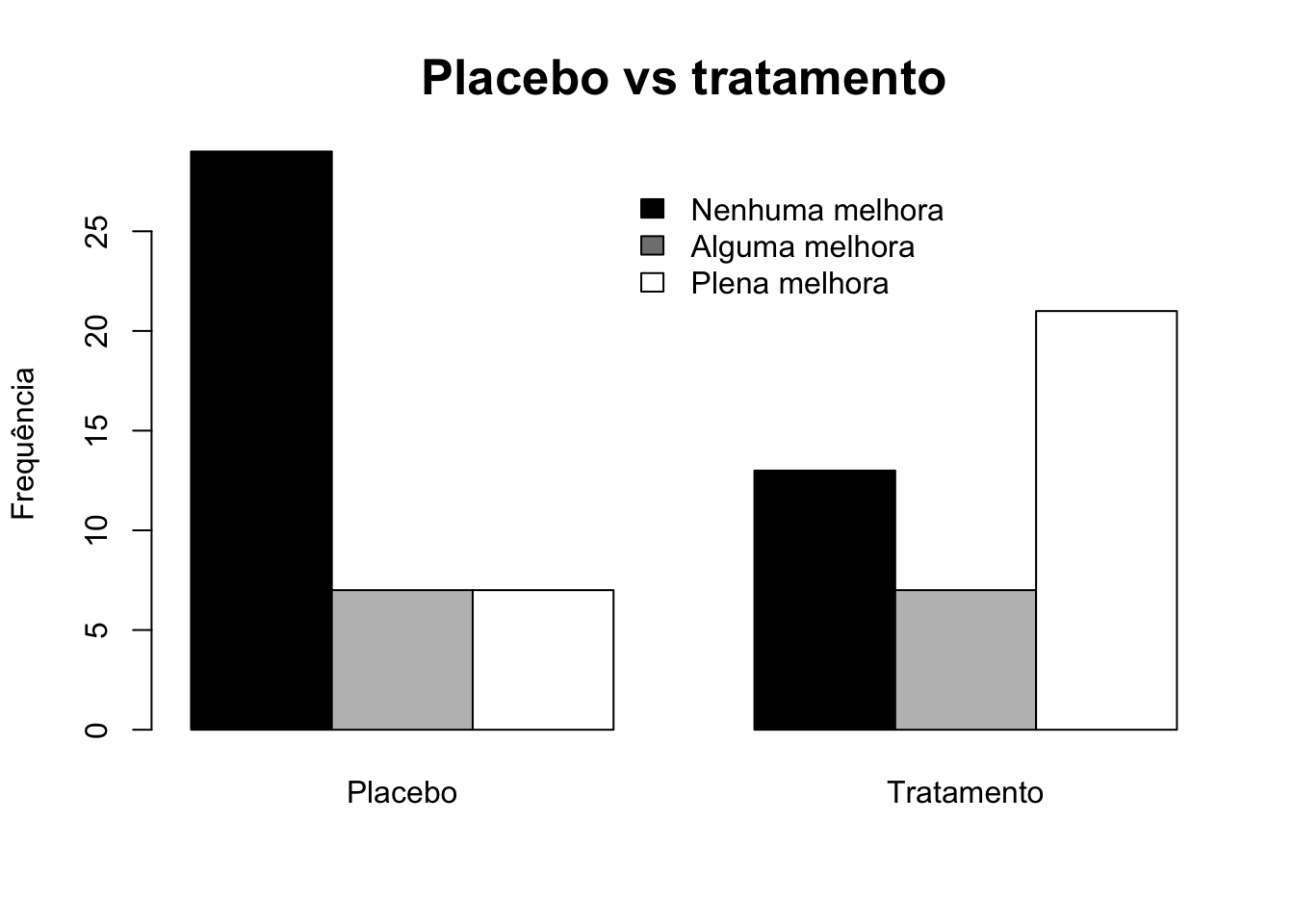
Exemplo 2.106 Em Python.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Dados
custos = np.array([760, 640, 75, 850, 100])
nomes_custos = ['A', 'B', 'C', 'D', 'E'] # Letras como nomes
# Gráfico de barras horizontais
plt.figure(figsize=(8, 4))
plt.barh(nomes_custos, custos, color=plt.cm.gray(np.arange(5)/4))
plt.xlabel('Custo (R$)', fontsize=12)
plt.title('Custos pessoais', fontsize=16)
plt.show()
# Gráfico de barras verticais
plt.figure(figsize=(8, 4))
plt.bar(nomes_custos, custos, color=plt.cm.gray(np.arange(5)/4))
plt.ylabel('Custo (R$)', fontsize=12)
plt.title('Custos pessoais', fontsize=16)
plt.show()
# Dados para o gráfico de colunas empilhadas
data = {'Improved': ['None', 'None', 'None', 'Some', 'Some',
'Some', 'Marked', 'Marked', 'Marked'],
'Treatment': ['Placebo', 'Treated', 'Placebo', 'Treated',
'Placebo', 'Treated', 'Placebo', 'Treated'],
'Frequency': [29, 7, 13, 14, 7, 21, 5, 2]}
df = pd.DataFrame(data)
trat = df.pivot(index='Improved', columns='Treatment',
values='Frequency')
# Gráfico de colunas empilhadas
trat.plot(kind='bar', stacked=True, color=['black','grey','white'])
plt.ylabel('Frequência', fontsize=12)
plt.title('Placebo vs Tratamento', fontsize=16)
plt.legend(title='Melhora', loc="upper left")
plt.show()
# Gráfico de colunas lado a lado
trat.plot(kind='bar', stacked=False, color=['black','grey','white'])
plt.ylabel('Frequência', fontsize=12)
plt.title('Placebo vs Tratamento', fontsize=16)
plt.legend(title='Melhora', loc="upper left")
plt.show()2.6.2.3 Histograma
The histogram is the classical nonparametric density estimator, probably dating from the mortality studies of John Graunt in 1662. (Scott 1979, 605)
O histograma é um gráfico de barras sem espaçamento utilizado para representar distribuições de frequência de variáveis contínuas. O termo foi introduzido por Karl Pearson “em suas palestras sobre estatística como um termo para uma forma comum de representação gráfica, ou seja, por colunas marcando como áreas a frequência correspondente ao alcance de sua base”. (Pearson 1895, 399)
Apresenta-se a variável dividida em classes no eixo horizontal (\(x\)) e a frequência de cada classe no eixo vertical (\(y\)). Os pacotes computacionais em geral definem o número de classes pela regra de Sturges conforme Eq. (2.3). É uma ferramenta básica de análise exploratória de dados para avaliar a dispersão e forma dos dados, detectar valores atípicos e sugerir modelos e transformações para análises mais avançadas.
Exemplo 2.107 Em R.
# Dados
h <- read.csv('https://filipezabala.com/data/hospital.csv',
header = TRUE)
# Histograma padrão
hist(h$height, prob = FALSE, right = FALSE, breaks = 'sturges',
main = '', xlab = 'Altura (m)', col = 'grey')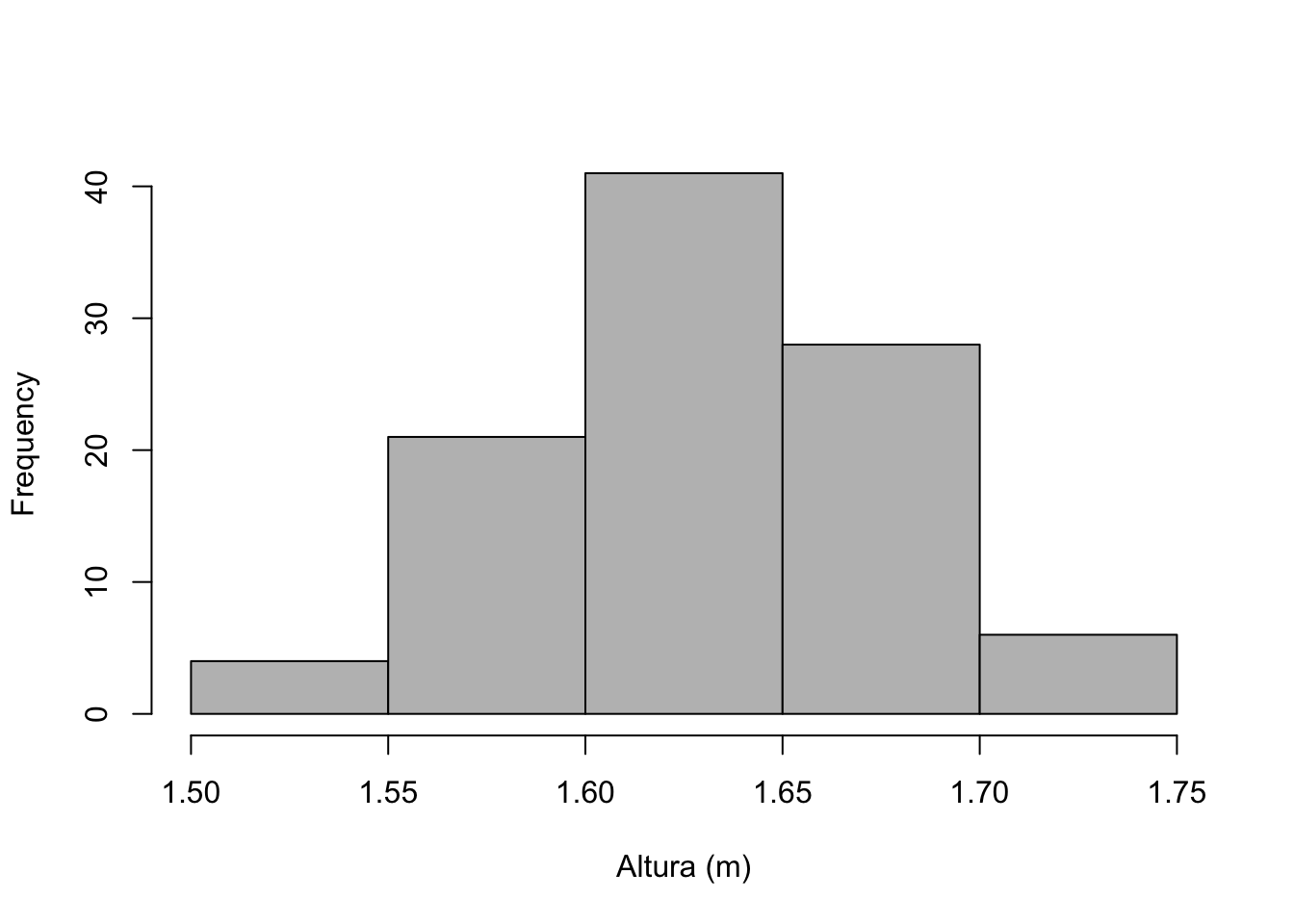
# Amplitude de classes de Freedman-Diaconis
hist(h$height, prob = TRUE, right = FALSE, breaks = 'fd',
main = '', xlab = 'Altura (m)', col = 'grey')
# Ajustando normal teórica
curve(dnorm(x, mean = mean(h$height), sd = sd(h$height)),
col = 'blue', lwd = 2, add = TRUE)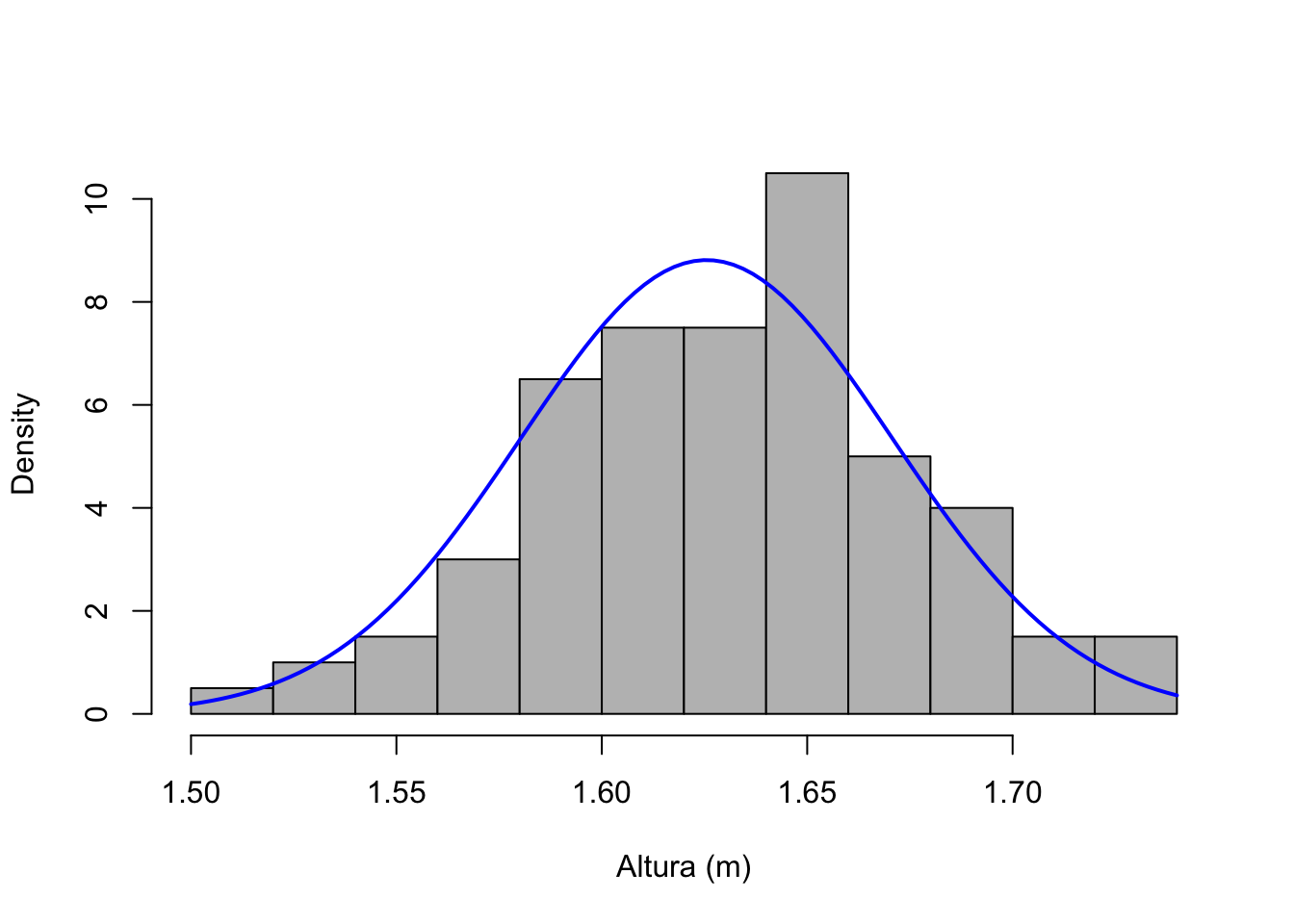
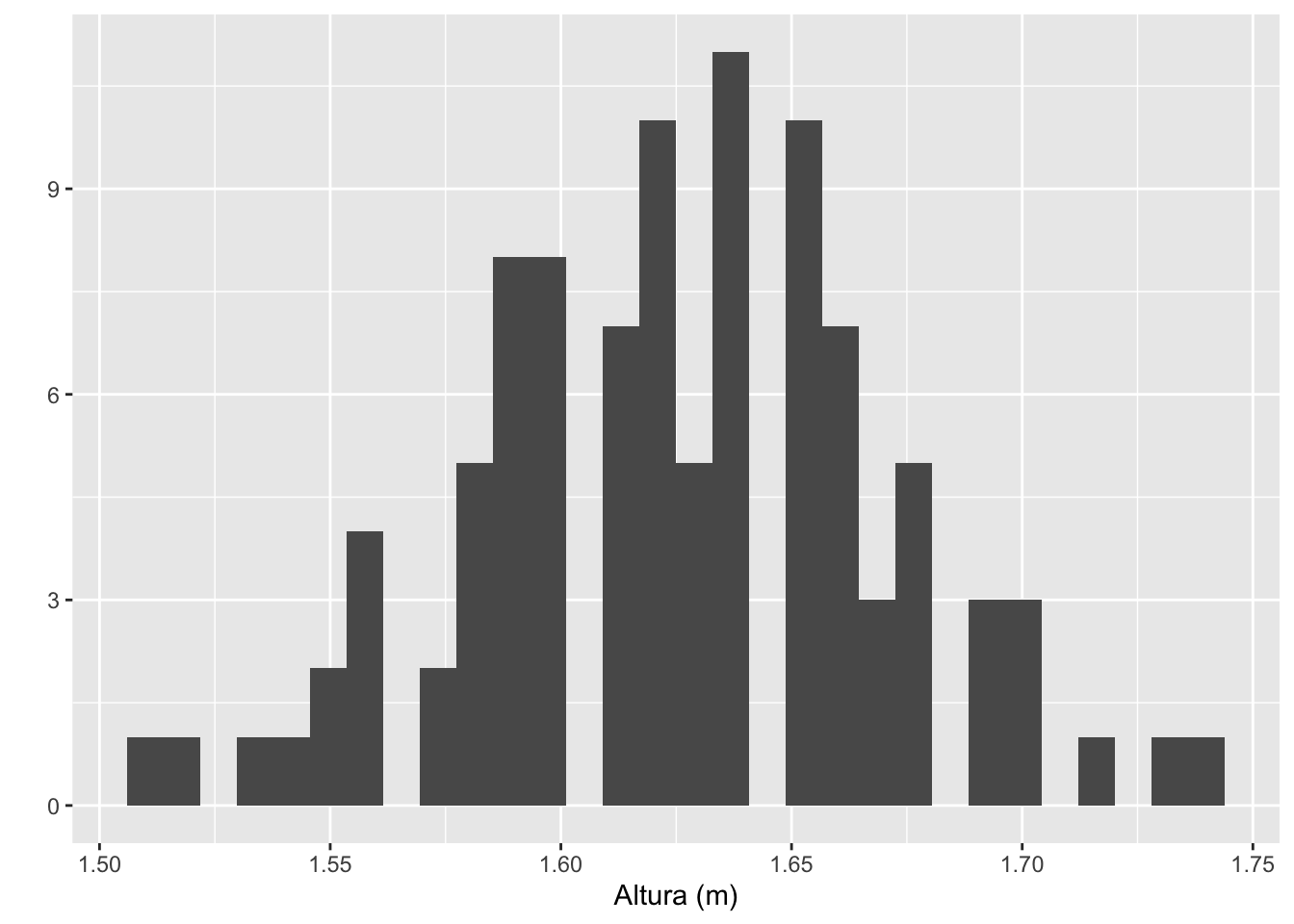
Exemplo 2.108 Em Python.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import norm
# Dados
h = pd.read_csv('https://filipezabala.com/data/hospital.csv')
# Histograma padrão
plt.hist(h['height'], bins='sturges', color='grey', align='left',
rwidth=0.8)
plt.xlabel('Altura (m)')
plt.ylabel('Frequência')
plt.title('Histograma da Altura')
plt.show()
# Histograma com amplitude de classes de Freedman-Diaconis
plt.hist(h['height'], bins='fd', color='grey', align='left',
rwidth=0.8, density=True)
plt.xlabel('Altura (m)')
plt.ylabel('Densidade')
plt.title('Histograma da Altura (Freedman-Diaconis)')
# Ajustando a curva normal teórica
x_min = h['height'].min()
x_max = h['height'].max()
x_range = np.linspace(x_min, x_max, 100)
y_norm = norm.pdf(x_range, loc=h['height'].mean(),
scale=h['height'].std())
plt.plot(x_range, y_norm, color='blue', linewidth=2)
plt.show()
# Histograma com ggplot2 (usando plotnine)
from plotnine import ggplot, aes, geom_histogram, labs
(ggplot(h, aes(x='height'))
+ geom_histogram(bins='sturges', fill='grey', color='black')
+ labs(x='Altura (m)', y='Frequência',
title='Histograma da Altura (ggplot2)')
)2.6.2.4 Boxplot
Introduzido por (Tukey 1977), o boxplot ou diagrama em caixa é um gráfico em formato retangular limitado pelo primeiro e terceiro quartis, onde a linha central é a mediana. A distância entre os quartis é a amplitude interquartílica conforme Seção 2.4.5 e contempla \(50\%\) dos dados centrais. Pontos que ultrapassam \(1.5\) vez a amplitude interquartílica acima (abaixo) de \(Q_{3}\) (\(Q_{1}\)) são chamados outliers. Variações são discutidas por (McGill et al. 1978), (Benjamini 1988) e (Esty and Banfield 2003).
Exemplo 2.109 Em R.
# Dados
h <- read.csv('https://filipezabala.com/data/hospital.csv',
header = TRUE)
# Boxplot
boxplot(h$children, main = 'Número de filhos',
ylab = 'Número de filhos', las = 1, cex.main = 1.6)
legend(1.31, 0.43, 'Mínimo', box.col = 'white')
arrows(x0 = 1.35, y0 = 0, x1 = 1.25, y1 = 0, length = 0.15)
legend(1.31, 1.42, 'Q1', box.col = 'white')
arrows(x0 = 1.35, y0 = 1, x1 = 1.25, y1 = 1, length = 0.15)
legend(1.31, 2.42, 'Mediana', box.col = 'white')
arrows(x0 = 1.35, y0 = 2, x1 = 1.25, y1 = 2, length = 0.15)
legend(1.31, 3.42, 'Q3', box.col='white')
arrows(x0 = 1.35, y0 = 3, x1 = 1.25, y1 = 3, length = 0.15)
legend(1.31, 6.42, 'Máximo', box.col = 'white')
arrows(x0 = 1.35, y0 = 6, x1 = 1.25, y1 = 6, length = 0.15)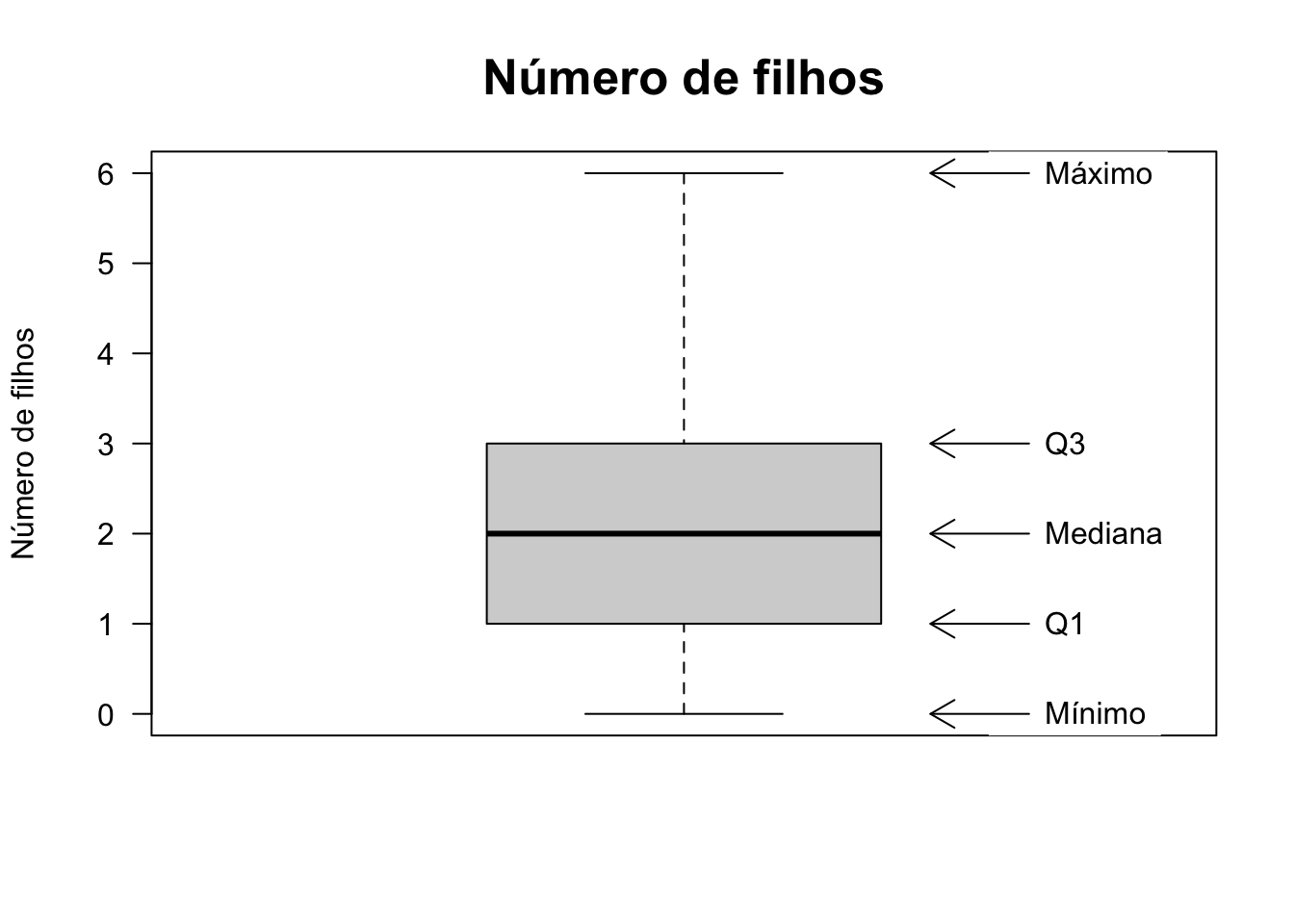
# Proporcional ao tamanho do grupo
set.seed(1); y <- c(rpois(50, lambda=1.5),rnorm(300,4),(1:150)/17)
x <- factor(c(rep('A',50), rep('B',300), rep('C',150) ))
bp <- boxplot(y ~ x, varwidth = TRUE, las = TRUE,
main = 'Variável W', cex.main = 1.6)
mtext(paste('(n=', bp$n, ')', sep = ''), at = seq_along(bp$n),
line = 2, side = 1)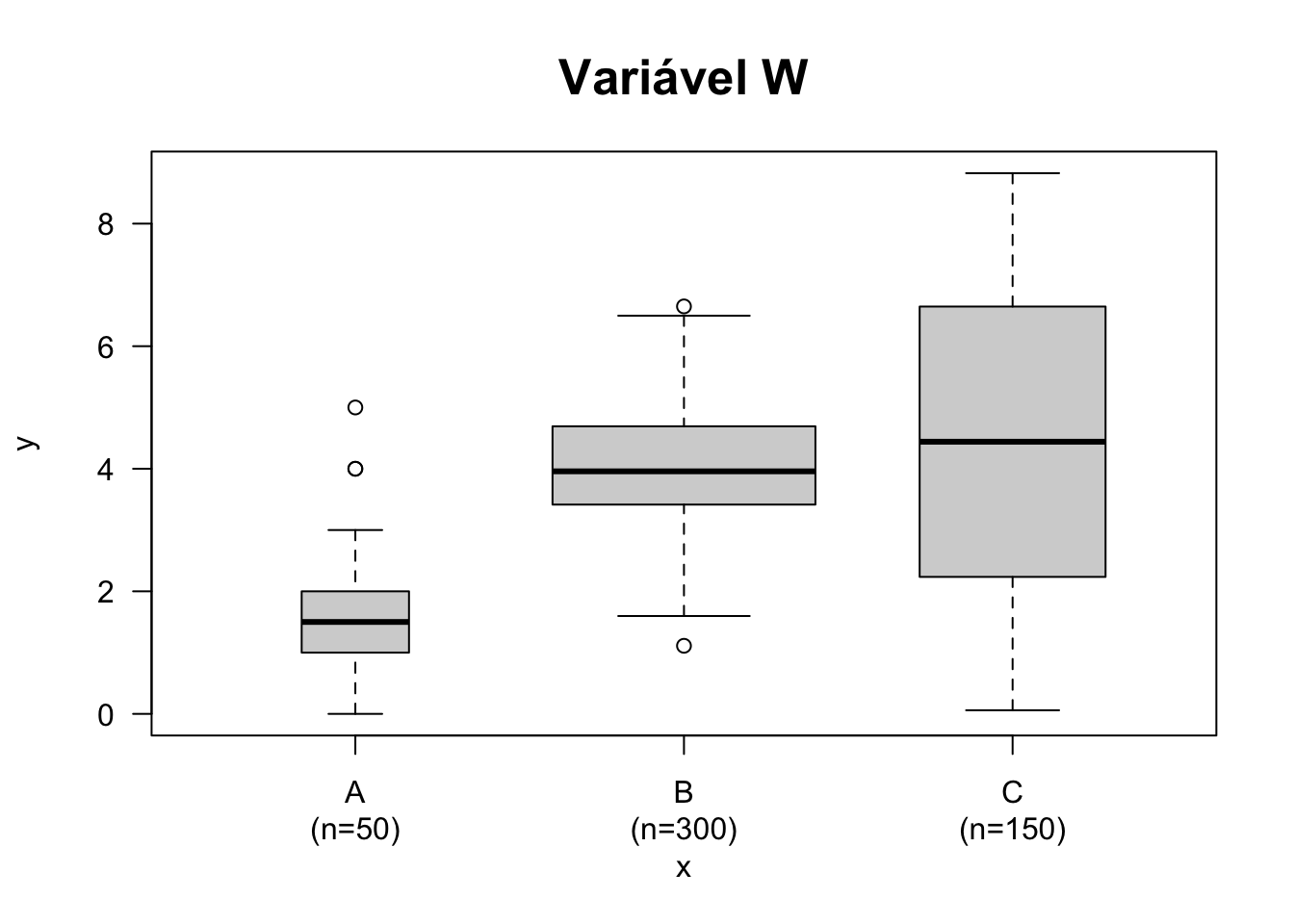
# Vertical (horizontal = TRUE)
boxplot(count ~ spray, data = InsectSprays, col = 'lightgray',
main = 'Pontuação em um teste', ylab = 'Pontos',
xlab = 'Grupo', las = 1, cex.main = 1.6, horizontal = FALSE)
legend(2.85, 18.5, 'Outliers', box.col = 'white')
arrows(x0 = 3.4,y0 = 15, x1 = 3.05, y1 = 7.8, length = 0.15)
arrows(x0 = 3.4,y0 = 15, x1 = 3.9, y1 = 12.3, length = 0.15)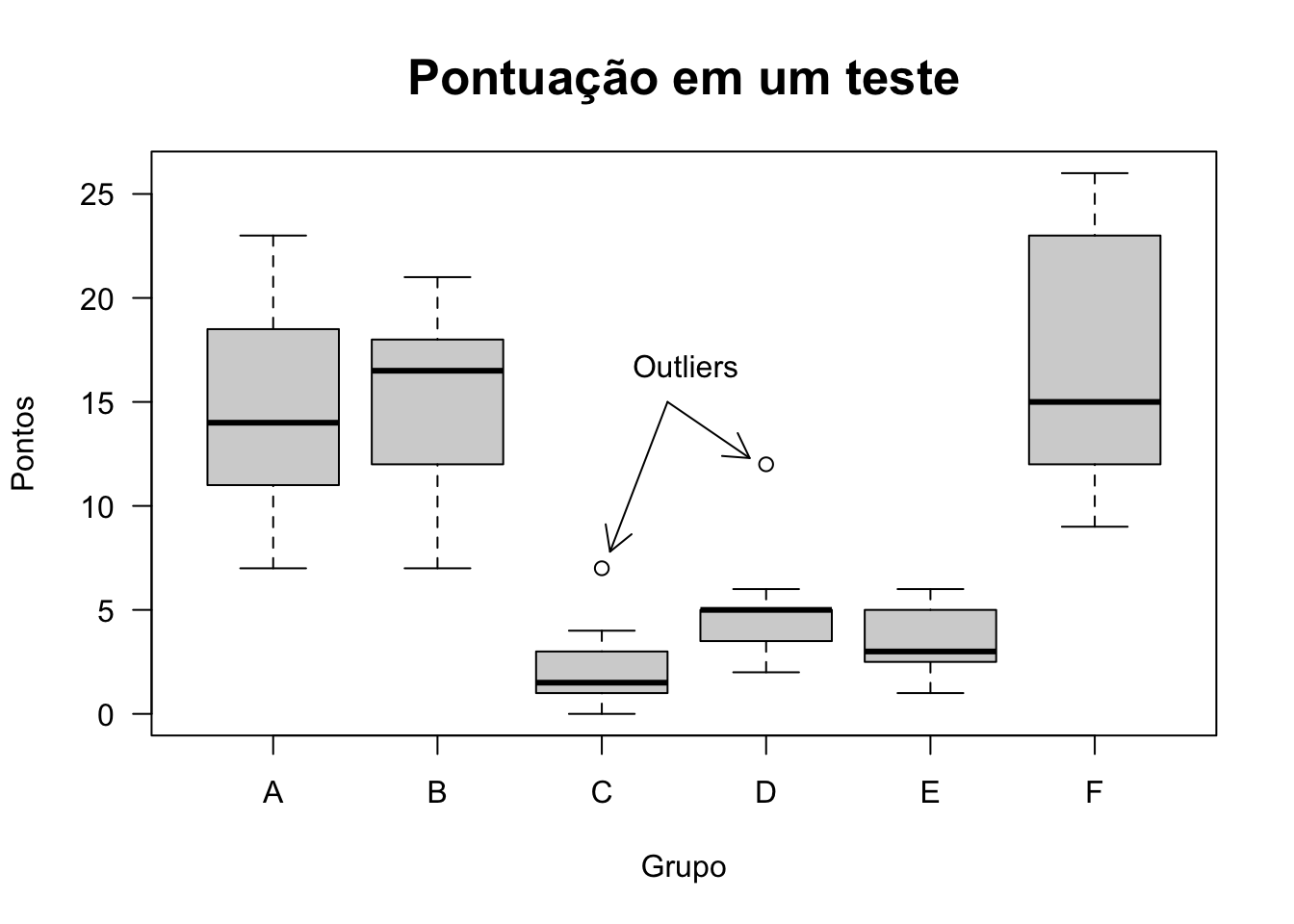
Exemplo 2.110 Em Python.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import norm
# Dados
h = pd.read_csv('https://filipezabala.com/data/hospital.csv')
# Boxplot
plt.figure(figsize=(8, 6))
plt.boxplot(h['children'], vert=False, patch_artist=True,
boxprops=dict(facecolor='lightgray'))
plt.xlabel('Número de filhos', fontsize=12)
plt.title('Número de filhos', fontsize=16)
# Adicionando as legendas e setas
plt.annotate('Mínimo', xy=(0, 0), xytext=(1.1, 0.1),
arrowprops=dict(arrowstyle='->'))
plt.annotate('Q1', xy=(1, 1), xytext=(1.1, 1.1),
arrowprops=dict(arrowstyle='->'))
plt.annotate('Mediana', xy=(2, 2), xytext=(1.1, 2.1),
arrowprops=dict(arrowstyle='->'))
plt.annotate('Q3', xy=(3, 3), xytext=(1.1, 3.1),
arrowprops=dict(arrowstyle='->'))
plt.annotate('Máximo', xy=(6, 6), xytext=(1.1, 6.1),
arrowprops=dict(arrowstyle='->'))
plt.show()
# Boxplot proporcional ao tamanho do grupo
np.random.seed(1)
y = np.concatenate([np.random.poisson(lam=1.5, size=50),
np.random.normal(loc=4, scale=1, size=300),
np.arange(1, 151) / 17])
x = np.array(['A'] * 50 + ['B'] * 300 + ['C'] * 150)
df = pd.DataFrame({'x': x, 'y': y})
plt.figure(figsize=(8, 6))
boxprops = dict(linestyle='-', linewidth=1.5, color='black')
medianprops = dict(linestyle='-', linewidth=2, color='red')
bp = df.boxplot(column='y', by='x', ax=plt.gca(),
widths=df['x'].value_counts(normalize=True),
boxprops=boxprops, medianprops=medianprops,
patch_artist=True, showmeans=True, meanline=True,
showfliers=False)
for i, (name, group) in enumerate(df.groupby('x')):
plt.text(i + 1, -2, f'(n={len(group)})', ha='center')
plt.suptitle('')
plt.title('Variável W', fontsize=16)
plt.xlabel('Grupo')
plt.ylabel('Valor')
plt.show()
# Boxplots vertical e horizontal com InsectSprays
url = 'https://raw.githubusercontent.com/vincentarelbundock/Rdatasets/master/csv/datasets/InsectSprays.csv'
insect_sprays = pd.read_csv(url)
# Vertical
plt.figure(figsize=(8, 6))
insect_sprays.boxplot(column='count', by='spray', grid=False,
patch_artist=True,
boxprops=dict(facecolor='lightgray'))
plt.ylabel('Contagem', fontsize=12)
plt.title('Contagem de Insetos por Spray', fontsize=16)
plt.suptitle('')
plt.xlabel('Spray')
plt.annotate('Outliers', xy=(3.4, 15), xytext=(2.85, 18.5),
arrowprops=dict(arrowstyle='->'))
plt.show()2.6.2.5 Gráfico de Dispersão
O gráfico de dispersão apresenta a relação entre duas variáveis numéricas. É uma ferramenta útil no ajuste dos modelos apresentados no Capítulo 7.
Exemplo 2.111 Em R.
performance <- 0.42515199183708*mtcars$mpg
weight <- 0.453592*mtcars$wt*1000
displacement <- 16.387064*mtcars$disp
rear_axle_ratio <- mtcars$drat
# Gráfico de dispersão
plot(weight, performance,
main = 'Performance (km/L) vs Weight (kg)',
xlab = 'Car weight (kg)',
ylab = 'Performance (km/L)',
pch = 19, las = 1, cex.main = 1.6)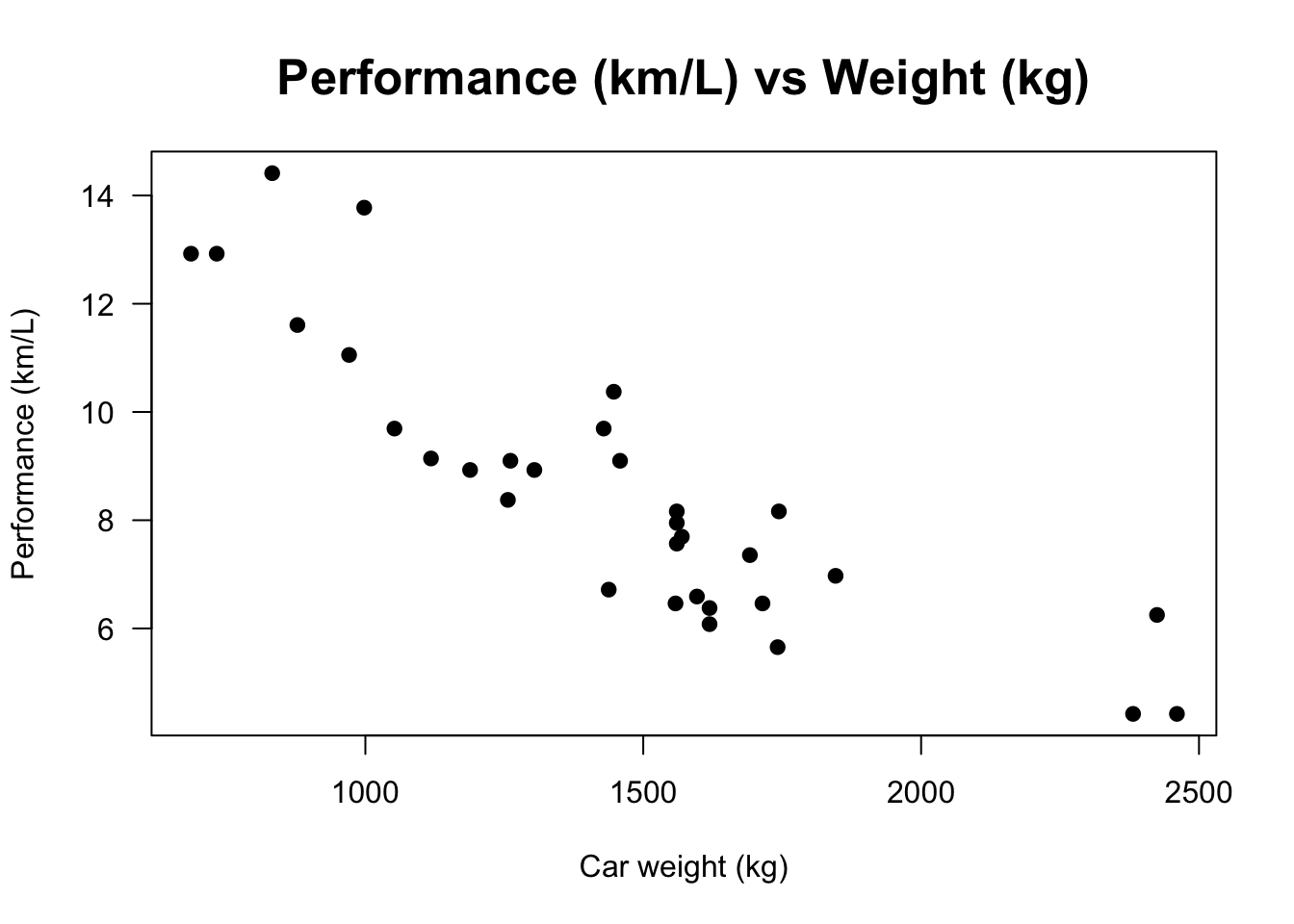
# Matriz de dispersão
pairs(~ performance + weight + displacement + rear_axle_ratio,
main = 'Scatter matrix', cex.main = 1.6)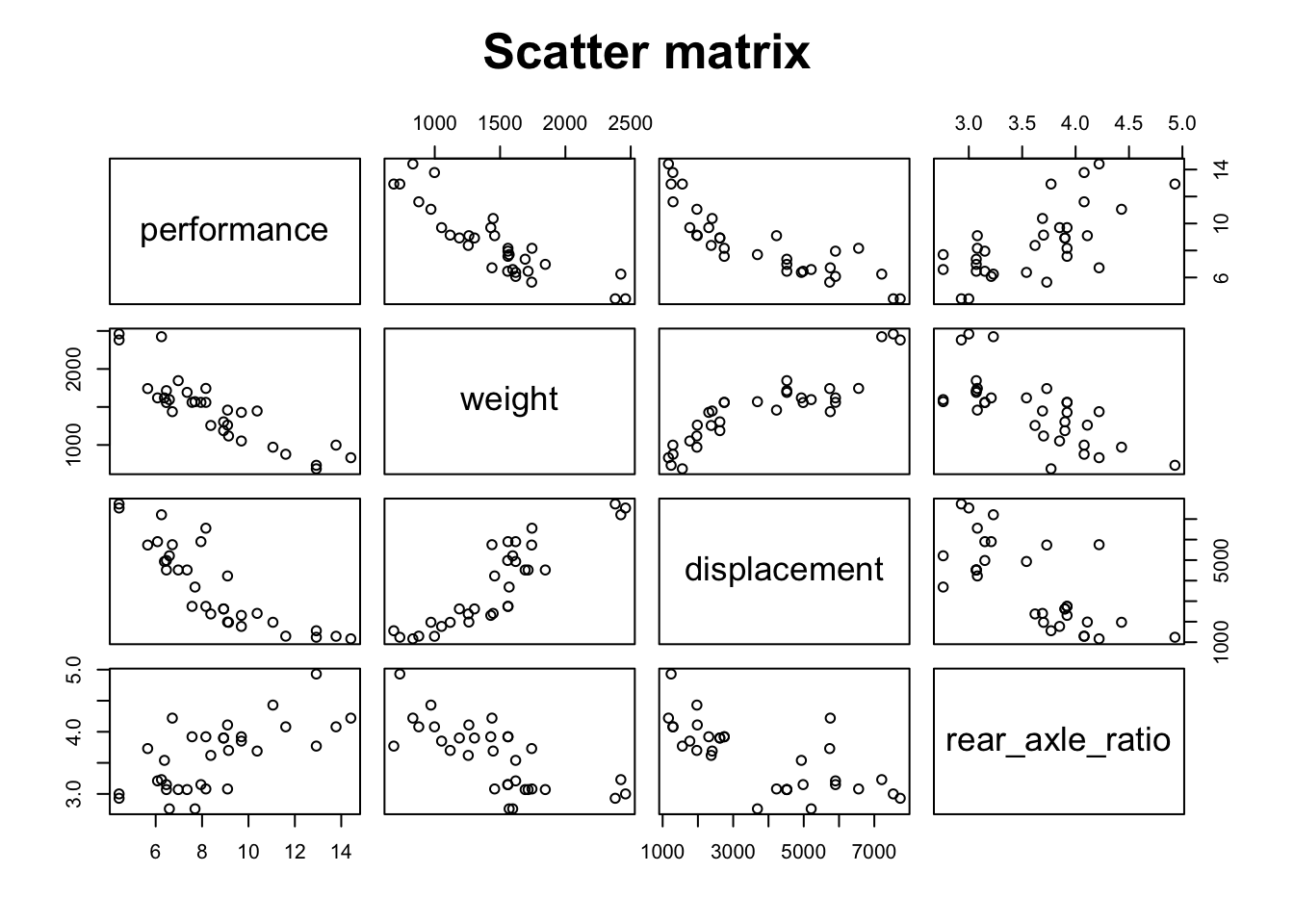
Exemplo 2.112 Em Python.
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
# Dados
df = pd.DataFrame({
'performance': 0.42515199183708 * pd.Series(mtcars['mpg']),
'weight': 0.453592 * pd.Series(mtcars['wt']) * 1000,
'displacement': 16.387064 * pd.Series(mtcars['disp']),
'rear_axle_ratio': pd.Series(mtcars['drat'])
})
# Gráfico de dispersão
plt.figure(figsize=(8, 6))
plt.scatter(df['weight'], df['performance'], color='blue', marker='o')
plt.xlabel('Peso do carro (kg)', fontsize=12)
plt.ylabel('Performance (km/L)', fontsize=12)
plt.title('Performance (km/L) vs Peso (kg)', fontsize=16)
plt.show()
# Matriz de dispersão
sns.pairplot(df)
plt.suptitle('Matriz de Dispersão', y=1.02, fontsize=16)
plt.show()2.6.2.6 Correlograma
Exemplo 2.113 Em R, adaptado de http://www.r-graph-gallery.com/97-correlation-ellipses/.
# Bibliotecas
library(ellipse)
library(RColorBrewer)
# Usando o famoso banco de dados 'mtcars'
data <- cor(mtcars)
# Painel de 100 cores com Rcolor Brewer
my_colors <- brewer.pal(5, "Spectral")
my_colors <- colorRampPalette(my_colors)(100)
# Ordenando a matriz de correlação
ord <- order(data[1, ])
data_ord <- data[ord, ord]
plotcorr(data_ord, col=my_colors[data_ord*50+50], mar=c(1,1,1,1))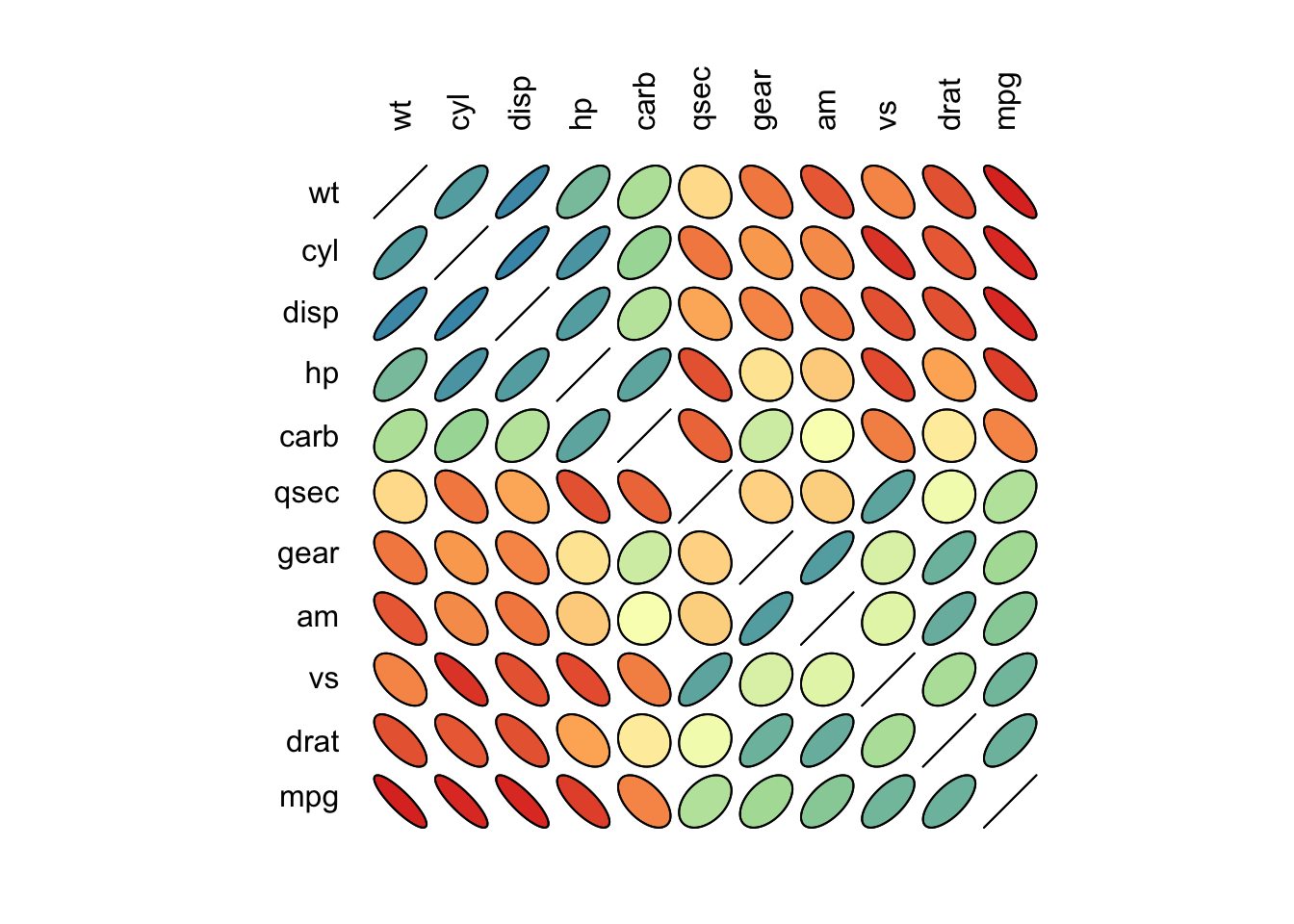
Adaptado de http://r-statistics.co/Top50-Ggplot2-Visualizations-MasterList-R-Code.html#Correlogram.
# Bibliotecas
library(ggplot2)
library(ggcorrplot)
# Matriz de correlação
data(mtcars)
corr <- round(cor(mtcars), 1)
# Gráfico
ggcorrplot(corr, hc.order = TRUE,
type = 'lower',
lab = TRUE,
lab_size = 3,
method = 'circle',
colors = c('tomato2', 'white', 'springgreen3'),
title = 'Correlograma de mtcars',
ggtheme = theme_bw)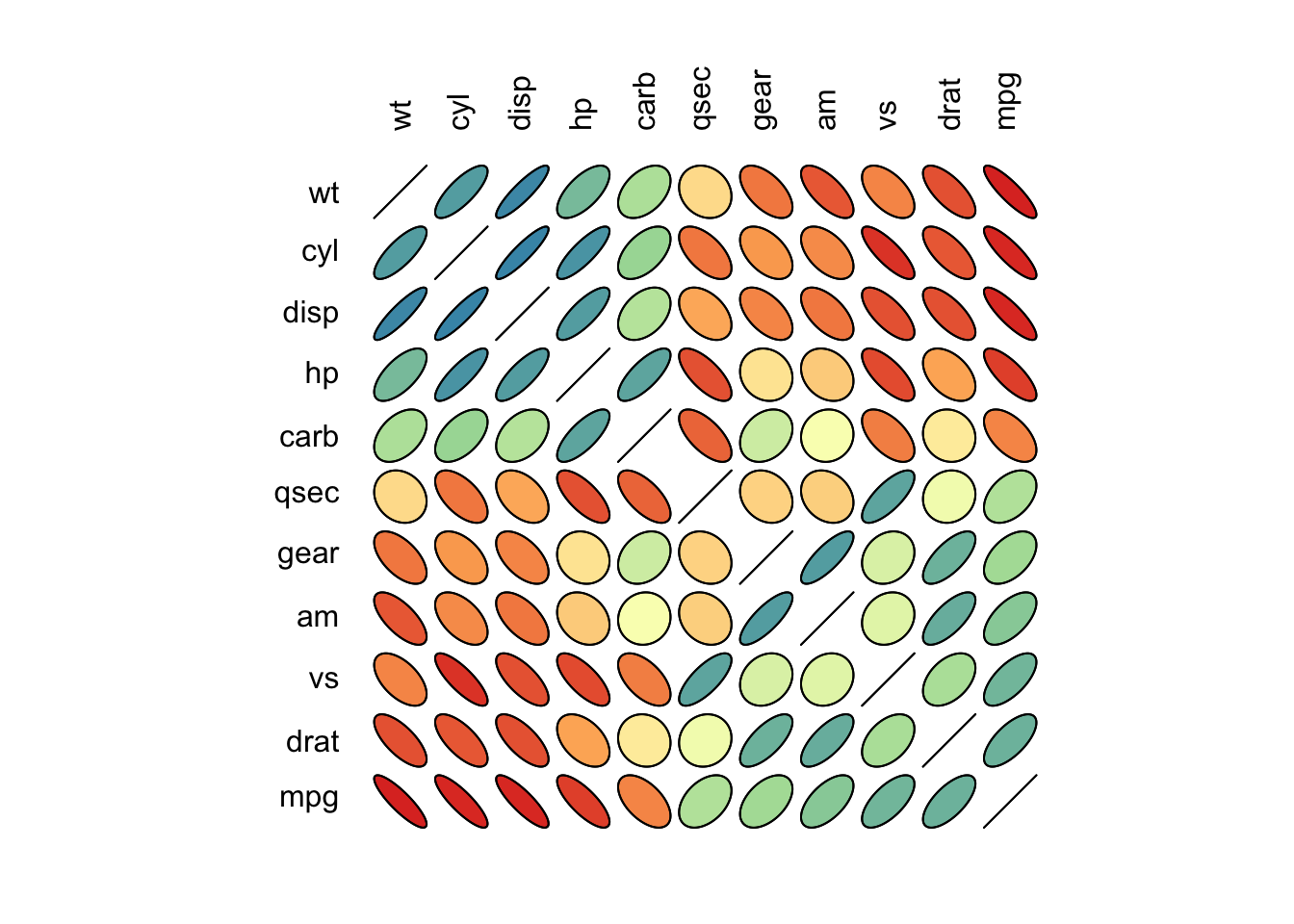
Exemplo 2.114 Em Python.
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
# Dados
data = mtcars.corr()
# Criando a paleta de cores
cmap = sns.color_palette("Spectral", as_cmap=True)
# Ordenando a matriz de correlação
data_ord = data.iloc[data.iloc[:, 0].abs().argsort(),
data.iloc[:, 0].abs().argsort()]
# Plotando a matriz de correlação
plt.figure(figsize=(10, 10))
sns.heatmap(data_ord, annot=True, cmap=cmap, fmt=".2f", linewidths=.5,
cbar_kws={'label': 'Correlação'})
plt.title('Matriz de Correlação Ordenada', fontsize=16)
plt.show()2.6.4 Para saber mais
- Krause, Rennie and the Royal Statistical Society (2023), agradeço a Luiz Eduardo de Souza pela sugestão.
- Kabakoff (2020-12-01) - Data Visualization with R
- Wilke (2019-04-30) - Fundamentals of Data Viz
- Healy (2018-04-25) - Data Visualization: A practical introduction
- Ben Fry (2007) - Visualizing Data
References
(Fitzpatrick 1960, 38) considera o engenheiro escocês William Playfair como “o fundador dos métodos gráficos estatísticos”.↩︎
https://www.karim.news/, https://www.instagram.com/karim_douieb/, https://twitter.com/karim_douieb.↩︎
https://twitter.com/karim_douieb/status/1591401816956481536?s=20↩︎
https://twitter.com/Twouttter/status/1635941366747258883?s=20↩︎