2.5 Outras medidas
2.5.1 Assimetria (ou Obliquidade)
Assimetria é uma medida que avalia a assimetria de uma distribuição de frequência. Existem diversas definições na literatura, das quais apresentam-se três alternativas. \[\begin{equation} g_1 = \dfrac{m_3}{m_2^{3/2}} = \dfrac{\frac{1}{n} \sum_{i=1}^{n} (x_{i} - \bar{x}_n)^3}{\left[ \frac{1}{n} \sum_{i=1}^{n} (x_{i} - \bar{x}_n)^2 \right]^{3/2}} \tag{2.41} \end{equation}\]
\[\begin{equation} b_1 = g_{1} \left( \dfrac{n-1}{n} \right)^{3/2} = \dfrac{m_3}{s^3} = \dfrac{\frac{1}{n} \sum_{i=1}^{n} (x_{i} - \bar{x}_n)^3 }{\left[ \frac{1}{n-1} \sum_{i=1}^{n} (x_{i} - \bar{x}_n)^2 \right]^{3/2}} \tag{2.42} \end{equation}\]
\[\begin{eqnarray} G_1 = g_{1} \sqrt{\dfrac{n(n-1)}{n-2}} = b_{1} \dfrac{n^2}{(n-1)(n-2)} \tag{2.43} \end{eqnarray}\]
Exemplo 2.90 Assimetria na distribuição normal.
# Gerando 100 valores N(0,1) com semente fixa
set.seed(1); x <- rnorm(100)
# Definição clássica de assimetria, Eq. (2.41)
e1071::skewness(x, type = 1)## [1] -0.0722319## [1] -0.07333656## [1] -0.07115113Exemplo 2.91 Em Python.
import numpy as np
from scipy.stats import skew
# Define a semente para reprodutibilidade
np.random.seed(1)
# Gerando 100 valores de uma distribuição normal padrão
x = np.random.normal(size=100)
# Assimetria tipo 1 (definição clássica)
skewness_type1 = skew(x, bias=False)
print(skewness_type1)
# Assimetria tipo 2 (usada em SAS, SPSS e Excel)
skewness_type2 = skew(x,bias=False)*np.sqrt(len(x)*(len(x)-1))/(len(x)-2)
print(skewness_type2)
# Assimetria tipo 3 (padrão do R, usada em MINITAB e BMDP)
skewness_type3 = skew(x,bias=False)*np.sqrt(len(x)*(len(x)-1))/(len(x)-2)*((len(x)-1)/len(x))**(3/2)
print(skewness_type3)Exemplo 2.92 Assimetria na distribuição qui-quadrado
# Gerando 100 valores X^2(1) com semente fixa
set.seed(1); x <- rchisq(100,1)
# Definição clássica de assimetria, Eq. (2.41)
e1071::skewness(x, type = 1)## [1] 3.01709## [1] 3.063232## [1] 2.971947Exemplo 2.93 Em Python.
import numpy as np
from scipy.stats import skew
# Define a semente para reprodutibilidade
np.random.seed(1)
# Gerando 100 valores de uma distribuição qui-quadrado com 1 gl
x = np.random.chisquare(df=1, size=100)
# Assimetria tipo 1 (definição clássica)
skewness_type1 = skew(x, bias=False)
print(skewness_type1)
# Assimetria tipo 2 (usada em SAS, SPSS e Excel)
skewness_type2 = skew(x,bias=False)*np.sqrt(len(x)*(len(x)-1))/(len(x)-2)
print(skewness_type2)
# Assimetria tipo 3 (padrão do R, usada em MINITAB e BMDP)
skewness_type3 = skew(x,bias=False)*np.sqrt(len(x)*(len(x)-1))/(len(x)-2)*((len(x)-1)/len(x))**(3/2)
print(skewness_type3)2.5.2 Curtose
A curtose é uma medida de achatamento de uma distribuição de frequência. Assim como na assimetria, das diversas definições de curtose apresentam-se três alternativas.
\[\begin{eqnarray} g_2 = \dfrac{m_4}{m_2^{2}} - 3 = \dfrac{\frac{1}{n} \sum_{i=1}^{n} (x_{i} - \bar{x}_n)^4}{\left[ \frac{1}{n} \sum_{i=1}^{n} (x_{i} - \bar{x}_n)^2 \right]^{2}} - 3 \tag{2.44} \end{eqnarray}\]
\[\begin{eqnarray} b_2 = (g_2 + 3) \left( 1 - \dfrac{1}{n} \right)^{2} - 3 = \dfrac{m_4}{s^4} - 3 = \dfrac{\frac{1}{n} \sum_{i=1}^{n} (x_{i} - \bar{x}_n)^4 }{\left[ \frac{1}{n-1} \sum_{i=1}^{n} (x_{i} - \bar{x}_n)^2 \right]^{2}} - 3 \tag{2.45} \end{eqnarray}\]
\[\begin{eqnarray} G_2 = \dfrac{ \left[ (n+1) g_2 + 6 \right] (n-1)}{(n-2)(n-3)} \tag{2.46} \end{eqnarray}\]
Exemplo 2.94 Curtose na distribuição normal.
# Gerando 100 valores N(0,1) com semente fixa
set.seed(1); x <- rnorm(100)
# Definição clássica de curtose, Eq. (2.44)
e1071::kurtosis(x, type = 1)## [1] 0.007653206## [1] 0.07053697## [1] -0.05219909Exemplo 2.95 Em Python.
import numpy as np
from scipy.stats import kurtosis
# Define a semente para reprodutibilidade
np.random.seed(1)
# Gerando 100 valores de uma distribuição normal padrão
x = np.random.normal(size=100)
# Curtose tipo 1 (definição clássica)
kurtosis_type1 = kurtosis(x, bias=False, fisher=False)
print(kurtosis_type1)
# Curtose tipo 2 (usada em SAS, SPSS e Excel)
kurtosis_type2 = kurtosis(x,bias=False,fisher=True)*(len(x)-1)/((len(x)-2)*(len(x)-3))*(len(x)+1)+3
print(kurtosis_type2)
# Curtose tipo 3 (padrão do R, usada em MINITAB e BMDP)
kurtosis_type3 = kurtosis(x,bias=False,fisher=True)*(len(x)+1)*(len(x)-1)/((len(x)-2)*(len(x)-3))
print(kurtosis_type3)Exemplo 2.96 Curtose na distribuição qui-quadrado.
# Gerando 100 valores X^2(1) com semente fixa
set.seed(1); x <- rchisq(100,1)
# Definição clássica de curtose, Eq. (2.44)
e1071::kurtosis(x, type = 1)## [1] 9.918662## [1] 10.49555## [1] 9.661581Exemplo 2.97 Em Python.
import numpy as np
from scipy.stats import kurtosis
# Define a semente para reprodutibilidade
np.random.seed(1)
# Gerando 100 valores de uma distribuição qui-quadrado com 1 gl
x = np.random.chisquare(df=1, size=100)
# Curtose tipo 1 (definição clássica)
kurtosis_type1 = kurtosis(x,bias=False,fisher=False)
print(kurtosis_type1)
# Curtose tipo 2 (usada em SAS, SPSS e Excel)
kurtosis_type2 = kurtosis(x,bias=False,fisher=True)*(len(x)-1)/((len(x)-2)*(len(x)-3))*(len(x)+1)+3
print(kurtosis_type2)
# Curtose tipo 3 (padrão do R, usada em MINITAB e BMDP)
kurtosis_type3 = kurtosis(x,bias=False,fisher=True)*(len(x)+1)*(len(x)-1)/((len(x)-2)*(len(x)-3))
print(kurtosis_type3)2.5.3 Coeficiente de Gini
O coeficiente de Gini foi desenvolvido pelo estatístico italiano Corrado Gini (Gini 1912) como uma medida resumida da desigualdade de renda na sociedade, sendo a diferença média de todas as quantidades observadas. De acordo com a documentação da função DescTools::Gini() (Signorell 2025), o intervalo do coeficiente de Gini varia de 0 (nenhuma concentração) a \(\sqrt{\frac{n-1}{n}}\) (concentração máxima).
Geralmente é associado ao gráfico de concentração de riqueza introduzido alguns anos antes por Max O. Lorenz (Lorenz 1905). Quando G é baseado na curva de distribuição de renda de Lorenz, pode ser interpretado como a diferença de renda esperada entre dois indivíduos selecionados aleatoriamente da população (Sen 1997). De acordo com Ceriani and Verme (2012), Gini “apresentou nada menos que 13 formulações de seu índice”, indicando “também que Gini antecipou alguns dos desenvolvimentos que surgiram do estudo de seu índice”.
Exemplo 2.98 Adaptado da documentação de DescTools::Gini().
library(DescTools)
# vetor de rendas
x <- c(541, 1463, 2445, 3438, 4437, 5401, 6392, 8304, 11904, 22261)
# coeficiente de Gini via DescTools::Gini()
Gini(x) # 0.5134346## [1] 0.5134346# R
# x <- x[id <- order(x)]
# f.hat <- w/2 + c(0, head(cumsum(w), -1))
# wm <- Mean(x, w)
# res <- 2/wm * sum(w * (x - wm) * (f.hat - Mean(f.hat,
# w)))
# if (unbiased)
# res <- res * 1/(1 - sum(w^2))
# return(res)
# ChatGTP 1
x <- x[id <- order(x)]
n <- length(x)
m <- mean(x)
soma1 <- 0
for(i in 1:n){
soma1 <- soma1 + sum(abs(x-x[i]))
}
(G1 <- soma1/(2*n^2*m)) # 0.4620911## [1] 0.4620911# ChatGTP 2
soma2 <- 0
for(i in 1:n){
soma2 <- soma2 + i*x[i]
}
(G2 <- (2*soma2)/(n*sum(x)) - (n+1)/n) # 0.4620911## [1] 0.4620911priceCarpenter <- d.pizza$price[d.pizza$driver=="Carpenter"]
priceMiller <- d.pizza$price[d.pizza$driver=="Miller"]
# compute the Lorenz curves
Lc.p <- Lc(priceCarpenter, na.rm=TRUE)
Lc.u <- Lc(priceMiller, na.rm=TRUE)
plot(Lc.p)
lines(Lc.u, col=2)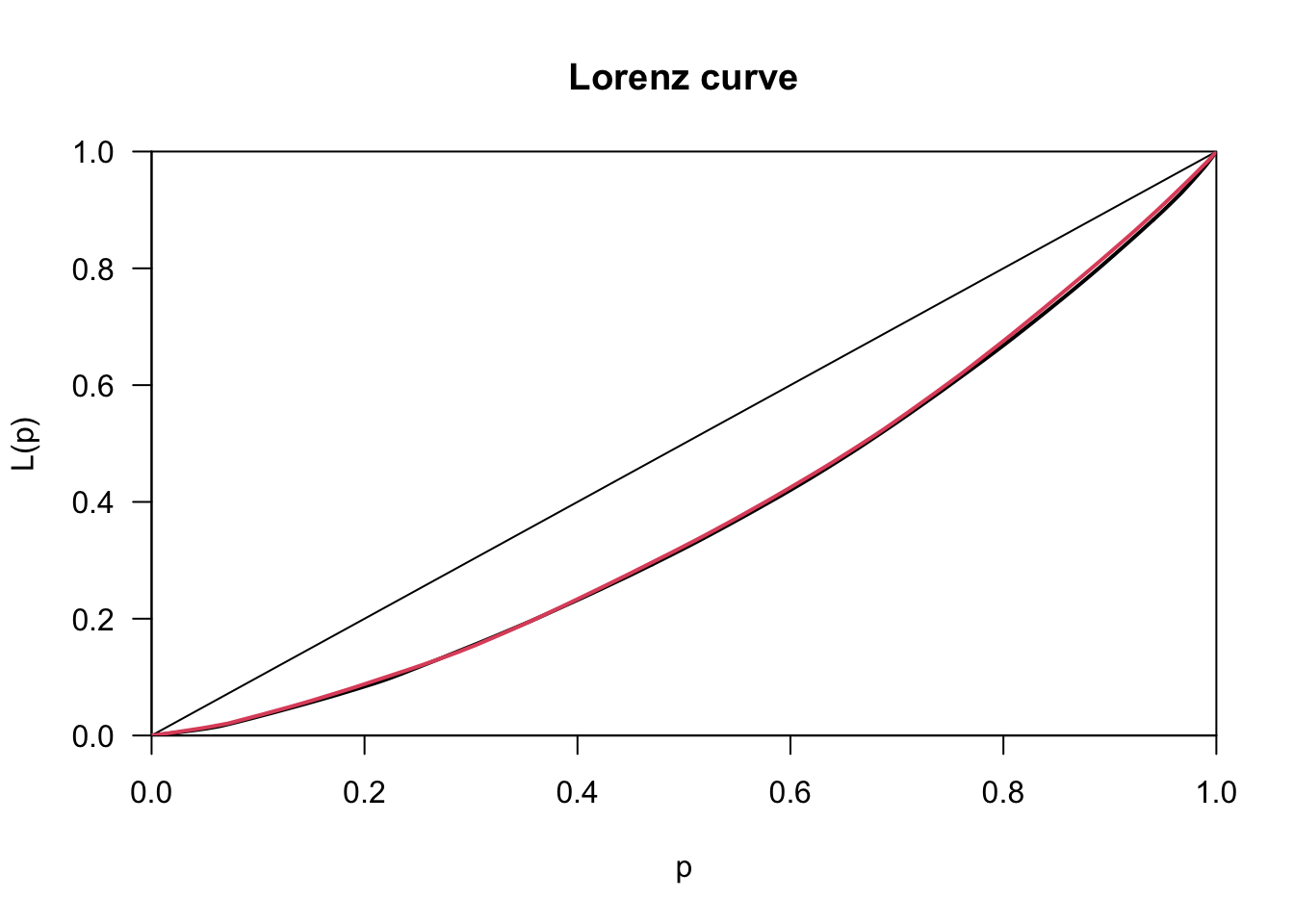
Exercício 2.14 Veja:
2.5.4 Índice de Theil
Os índices \(T\) e \(L\) de Theil são propostos por (Theil 1967).
2.5.4.1 \(T\) de Theil
(Theil 1967, 95) propõe na Eq. (1.9)14
\[\begin{equation} T = \sum_{i=1}^{N} \frac{y_i}{\sum_{j=1}^{N} y_j} \log \frac{\frac{y_i}{\sum_{j=1}^{N} y_j}}{\frac{1}{N}} \tag{2.47} \end{equation}\]
- \(N\): total de pessoas na população ou amostra.
- \(y_i\): renda do sujeito \(i=1,\ldots,N\).
- \(\sum_{j=1}^{N} y_j\): renda total da população ou amostra.
- \(\log\): logaritmo na base natural \(e \approx 2.718282\).
- \(0 \le T \le \log N\).
(Haughton and Khandker 2009) definem o índice \(T\) em função da média geral \(\bar{y}\).
\[\begin{equation} T = \frac{1}{N} \sum_{i=1}^{N} \frac{y_i}{\bar{y}} \log \frac{y_i}{\bar{y}} \\ \tag{2.48} \end{equation}\]
pois \[\sum_{j=1}^{N} y_j = N\bar{y}\] e \[\frac{\frac{y_i}{\sum_{j=1}^{N} y_j}}{\frac{1}{N}} = \frac{y_i}{\bar{y}}.\]
Ainda conforme Eq. (1.9) de (Theil 1967, 95), o índice \(T\) de Theil é decomponível em uma parcela entre (between) grupos \(T_B\) e uma parcela intra (within) grupo \(T_W\)
\[\begin{equation} T = T_B + T_W \tag{2.49} \end{equation}\]
onde
\[\begin{equation} T_B = \sum_{g=1}^G \frac{N_g}{N} \frac{\bar{y}_g}{\bar{y}} \log \frac{\bar{y}_g}{\bar{y}} \tag{2.50} \end{equation}\]
pois \[\frac{\sum_{k=1}^{N_g} y_k}{\sum_{j=1}^{N} y_j} = \frac{N_g}{N} \, \frac{\bar{y}_g}{\bar{y}}\]
- \(N_g\): número de pessoas do grupo \(g=1,\ldots,G\).
- \(\bar{y}_g\): média do grupo \(g=1,\ldots,G\).
- \(\bar{y}\): média geral.
\[\begin{equation} T_W = \sum_{g=1}^G \left( \frac{\sum_{k=1}^{N_g} y_k}{\sum_{j=1}^{N} y_j} \right) \left( \sum_{k=1}^{N_g} \frac{\frac{y_k}{\sum_{j=1}^{N} y_j}}{\frac{\sum_{k=1}^{N_g} y_k}{\sum_{j=1}^{N} y_j}} \log \frac{\frac{\frac{y_k}{\sum_{j=1}^{N} y_j}}{\frac{\sum_{k=1}^{N_g} y_k}{\sum_{j=1}^{N} y_j}}}{\frac{1}{N_g}} \right) \\ \tag{2.51} \end{equation}\]
Como \[\frac{\frac{y_k}{\sum_{j=1}^{N} y_j}}{\frac{\sum_{k=1}^{N_g} y_k}{\sum_{j=1}^{N} y_j}} = \frac{y_k}{\sum_{k=1}^{N_g} y_k} \] pode-se simplificar a Eq. (5), resultando em
\[\begin{equation} T_W = \frac{1}{N} \sum_{g=1}^G \frac{\bar{y}_g}{\bar{y}} \left( \sum_{k=1}^{N_g} \frac{y_k}{\bar{y}_g} \log \frac{y_k}{\bar{y}_g} \right) \tag{2.52} \end{equation}\]
References
A equação original de (Theil 1967, 95) é \(T=\sum_{i=1}^{N} y_i \log \frac{y_i}{1/N}\), onde \(y_i\) indica a proporção da renda do sujeito \(i\), i.e., \(y_i=\frac{\text{renda do sujeito } i}{\text{total da renda}}\).↩︎