6.3 Teste de Hipóteses
Exercício 6.9 Verifique a hipótese de que a palavra ‘hipótese’ vem do grego hipo (fraca) + tese = tese fraca conforme sugerido por Renato Janine Ribeiro no Provoca de 24/08/2021.
Sugestão: Capítulo 8 \(\\\)
6.3.1 Via intervalos de confiança
Os testes de hipóteses possuem as mesmas características e propriedades dos seus respectivos intervalos de confiança. Desta forma, apresenta-se um breve exemplo abordando a equivalência entre os TH e os IC para a proporção universal \(\pi\).
Exemplo 6.14 (TH \(\equiv\) IC) Suponha uma moeda com probabilidade de face cara \(Pr(H)=\pi\). Em princípio não sabemos o valor de \(\pi\), e pode ser interessante considerar duas configurações:
\[\left\{ \begin{array}{l} H_0: \mbox{a moeda é equilibrada}\\ H_1: \mbox{a moeda não é equilibrada}\\ \end{array} \right. \equiv \left\{ \begin{array}{l} H_0: \pi = 0.5 \\ H_1: \pi \ne 0.5 \\ \end{array} \right. \]
Aplicando a ideia de Charles Sanders Peirce de supor \(H_{0}\) verdadeira (ou ‘sob \(H_{0}\)’), espera-se observar ‘cara’ em 50% dos resultados, com alguma variação em torno de 50%. Considerando a Equação (6.8) pode-se obter a margem de erro esperada para esta oscilação em função do tamanho da amostra \(n\) para, digamos, 95% dos casos: \[ IC \left[ \pi, 95\% \right] = 0.5 \mp 1.96 \sqrt{\dfrac{0.5 \left(1-0.5\right)}{n}} = 0.5 \mp \dfrac{0.98}{\sqrt{n}} \]
Assim, ao realizar \(n=25\) lançamentos e observar uma frequência de caras no intervalo \[ IC \left[ \pi, 95\% \right] = 0.5 \mp \dfrac{0.98}{\sqrt{25}} = \left[ 0.304,0.696 \right] = \left[ 30.4\%,69.6\% \right] \] pode-se considerar a moeda equilibrada com \(1-\alpha=95\%\) de confiança. Caso a frequência seja inferior a \(30.4\%\) ou superior a \(69.6\%\), há indícios de que a moeda seja desequilibrada, também com 95% de confiança. Pela terminologia dos testes de hipóteses, não se rejeita \(H_{0}\) com \(\alpha=5\%\). Se \(n=100\), \[ IC \left[ \pi, 95\% \right] = 0.5 \mp \dfrac{0.98}{\sqrt{100}} = \left[ 0.402,0.598 \right] = \left[ 40.2\%,59.8\% \right] \] e obtém-se um intervalo menor se comparado a \(n=25\), i.e., mais preciso para a mesma confiança de 95%. Se Como exercício, use a função para definir outros valores para \(n\) e teste este resultado em uma moeda.
# IC95% sob H0: \pi=0.5
ic <- function(n){
cat('[', 0.5-.98/sqrt(n), ',',
0.5+.98/sqrt(n), ']')
}
ic(25)## [ 0.304 , 0.696 ]## [ 0.402 , 0.598 ]6.3.3 Espaço paramétrico
Seja um parâmetro \(\theta\) pertencente a um espaço paramétrico \(\Theta\), i.e., o conjunto de todos os possíveis valores de \(\theta\). Considere uma partição tal que \(\Theta_0 \cup \Theta_1 = \Theta\) e \(\Theta_0 \cap \Theta_1 = \emptyset\). Um teste de hipóteses é uma regra de decisão que permite decidir, à luz das informações disponíveis, se é mais verossímil admitir \(\theta \in \Theta_0\) ou \(\theta \in \Theta_1\). A hipótese que envolve \(\Theta_0\) é chamada hipótese nula, e a que envolve \(\Theta_1\) é a hipótese alternativa. Tais hipóteses podem ser escritas na forma
\[\left\{ \begin{array}{l} H_0: \theta \in \Theta_0\\ H_1: \theta \in \Theta_1 \\ \end{array} \right. \]
6.3.4 Hipótese nula \(H_0\)
Usualmente nos procedimentos de testes de hipóteses admite-se inicialmente que \(H_0\) seja verdadeira, dito sob a hipótese nula. Por este motivo a hipótese nula sempre deve conter a igualdade, o que indicado no quadro abaixo. Note que não há uma ‘regra da hipótese nula’, a indicação está colocada desta forma apenas por motivos didáticos.

6.3.5 Hipótese alternativa \(H_1\)
As definições do quadro acima implicam em três tipos de hipótese alternativa, conforme figura a seguir. Um teste bicaudal ou bilateral testa uma hipótese de equilíbrio, geralmente utilizada quando não há definição prévia sobre a direção da hipótese, tal como no caso de decidir se uma moeda deve ou não ser considerada equilibrada. O teste unicaudal inferior verifica a hipótese que indica um piso de referência, tal como no caso de decidir sobre a eficácia mínima de um tratamento (maior, melhor). O teste unicaudal superior avalia uma hipótese que indica um teto de referência, tal como no caso de decidir sobre a uma ação dependente de uma taxa máxima de mortalidade (menor, melhor).
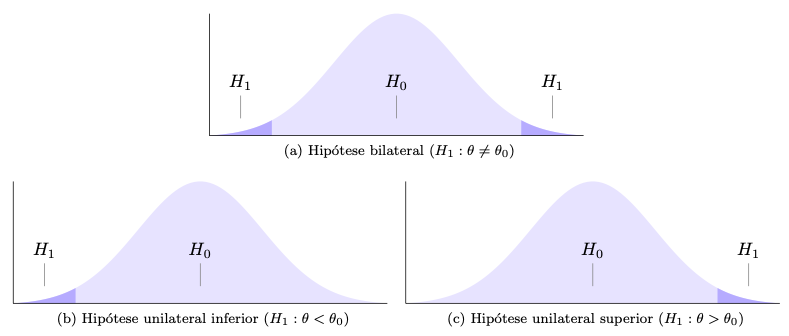
6.3.5.1 Procedimento para definição de hipótese estatística
- Escreva \[\left\{ \begin{array}{l} H_0: \\ H_1: \end{array} \right. \]
- Parâmetro.
- Valor.
- Hipótese alternativa.
Exercício 6.10 Para cada item abaixo, indique as hipóteses sendo testadas.
\(\;\) a. A companhia de transporte afirma que, em média, o intervalo entre sucessivos ônibus de uma determinada linha é de 15 minutos. Uma associação de usuários de transportes coletivos acha que a pontualidade é muito importante, e deseja testar a afirmação da companhia.
\(\;\) b. Os amortecedores de automóveis que circulam em cidades duram pelo menos 100 mil quilômetros em média, segundo a informação de algumas oficinas especializadas. O proprietário de uma locadora de veículos deseja testar esta afirmação.
\(\;\) c. Um veterinário afirma ter obtido um ganho médio diário de pelo menos 3 litros de leite por vaca com uma nova composição de ração. Um pecuarista acredita que o ganho não é tão grande assim.
\(\;\) d. Algumas garrafas de cerveja declaram em seus rótulos conter 600mL. Os órgãos de fiscalização desejam avaliar se uma fábrica deve ou não ser autuada por engarrafar cervejas com uma quantidade menor que o indicado no rótulo.
\(\;\) e. O dado de um cassino parece estar viciado, saindo o valor 1 com uma frequência muito grande.
\(\;\) f. Um fabricante afirma que a sua vacina previne pelo menos 80% dos casos de uma doença. Um grupo de médicos desconfia que a vacina não é tão eficiente assim. \(\\\)
6.3.6 Estatística do teste
A partir da premissa de que \(H_0\) é verdadeira, compara(m)-se o(s) valor(es) descrito(s) nesta hipótese com os dados da amostra através de uma medida chamada estatística de teste ou quantidade pivotal. Caso a estatística do teste indique uma pequena distância entre o(s) valor(es) de \(H_0\) e a estatística, admite-se ou não se rejeita \(H_0\); caso a distância seja grande, rejeita-se \(H_0\).
As distâncias que fazem admitir ou rejeitar \(H_0\) são avaliadas em termos probabilísticos, indicadas nos gráficos da Seção 6.3.5 respectivamente pelas regiões claras e escuras. A divisão destas regiões é dada por valores críticos, quantis das distribuições associadas que limitam a significância (\(\alpha\)) ou, de forma equivalente, a confiança (\(1-\alpha\)) desejadas.
6.3.7 Tipos de erro
O procedimento de teste de hipóteses clássico é baseado nos erros do tipo I e tipo II. Os valores de significância está associado à probabilidade de erro do tipo I, ou o caso em que erramos ao rejeitar uma hipótese \(H_0\) verdadeira. Tal valor de significâncie é arbitrário, ou seja, deve ser definido pelo decisor ao estipular o quanto admite de probabilidade máxima de erro do tipo I. O erro do tipo II indica o caso de errar ao não rejeitar uma hipótese \(H_0\) falsa.
6.3.8 Valor-p
É possível ainda considerar formas mais precisas de avaliar as distâncias probabilisticas das estatísticas de teste do que simplesmente indicando ‘acima’ ou ‘abaixo’ de um valor crítico. Pelo paradigma clássico, atribui-se uma medida que varia entre 0 e 1, chamada valor-p. Este medida possui múltiplas definições e ainda é bastante discutida na literatura, sendo frequentemente mal interpretada. A definição a seguir é baseada em (Carlos Alberto de B. Pereira and Wechsler 1993, 161). Considere um experimento produzindo dados \(x\), uma observação de \(X\), para testar uma hipótese simples \(H_0\) versus \(H_1\).
Definição 6.4 O valor-p é a probabilidade, sob \(H_0\), do evento composto por todos os pontos amostrais que favorecem \(H_1\) (contra \(H_0\)) serem tão o mais extremos do que \(x\).
Rejeita-se \(H_0\) se este grau de evidência for baixo, inferior a um valor de referência chamado (nível de) significância e representado por \(\alpha\); caso contrário, admite-se ou não se rejeita \(H_0\). Note que um um valor-p alto pode indicar ‘\(H_0\) é mais verossímil que \(H_1\)’ OU ‘não tenho informação para decidir entre \(H_0\) e \(H_1\)’. Este é o motivo do cuidado ao declarar ‘não se rejeita \(H_0\)’.

Existem valores de significância típicos, usualmente 10%, 5%, 1%, e 0.1%. Devido a um exemplo dado por [Ronald A. Fisher (1925)]28, o valor de 5% tornou-se uma referência para o valor de \(\alpha\), ainda que existam propostas mais elaboradas e melhor embasadas na teoria Estatística. Destacam-se os trabalhos de (Carlos Alberto de B. Pereira and Stern 2020), (Gannon, Pereira, and Polpo 2019) e (Carlos Alberto de B. Pereira and Wechsler 1993).
Exercício 6.11 Considere a imagem a seguir.

by imgflip.com
- Comente a frase do meme.
- Complete a frase: ‘If the p is high, …’. \(\\\)
Exercício 6.12 Acesse https://rpsychologist.com/pvalue/ e realize as simulações sugeridas.
Exemplo 6.15 (Momentinho Cultural) The P Value Song de Michael Greenacre & Gurdeep Stephens.
Statistics, logistics, cladistics seem to me
To have a common theme scientifically,
Economists, biologists, with PhD degrees,
They all need some proof of their theories.
A letter is the key, you’ll see clearly,
Not B nor G nor V – but it’s the P!
There’s no values like P-values
Like no values I know
Think of something that is not worth proving,
An hypothesis that everyone calls null,
If your P is too large to reject it
Then your experiment is rather dull.
There’s no values like P-values,
Especially when they are low,
Don’t be sad if your P’s over point-O-five,
Just try again with samples twice the size,
Everything is possible, just trust in me:
Put your faith in the P.
The F test, the Z test, the chi-square and the T
And other cryptic terminology
Anova, regression, tests distribution-free,
They all need some sort of guarantee.
So if you find a tiny effect size
The P-value will be a good disguise.
There’s no values like P-values,
The frequentist’s hero,
When you get that data modeling feeling
But results you have are not a lot,
You will need some stats that are appealing
To show the journals your work is hot!
There’s no values like P-values
Especially when they’re low
Don’t be sad if your P’s over point-O-five,
Just try again with samples twice the size
Everything is possible, just trust in me:
Put your faith in the P!
6.3.9 Paramétricos Univariados
6.3.9.1 Teste \(z\) para média de uma amostra
Hipótese avaliada Uma amostra de \(n\) sujeitos (ou objetos) vem de uma população de média \(\mu\) igual a um valor especificado \(\mu_0\)?
Suposições S1. O desvio padrão universal \(\sigma\) é conhecido. S2. A amostra foi selecionada aleatoriamente da população que representa. S3. A distribuição dos dados na população que a amostra representa é normal. Pelo Teorema Central do Limite, tal suposição torna-se menos importante à medida que o tamanho da amostra aumenta.
Testes relacionados TESTE 15 - Teste dos postos sinalizados de Wilcoxon para uma amostra
Estatística do teste Sob \(H_0: \mu = \mu_0\), \(H_0: \mu \ge \mu_0\) ou \(H_0: \mu \le \mu_0\), \[\begin{equation} z_{teste}=\frac{\bar{x}-\mu_0}{\sigma/\sqrt{n}} \sim \mathcal{N}(0,1). \tag{6.13} \end{equation}\]
Valor-p Sob \(H_0: \mu = \mu_0\), \[\begin{equation} \text{Valor-p} = 2Pr(Z \le -|z_{teste}|). \tag{6.14} \end{equation}\]
Sob \(H_0: \mu \ge \mu_0\), \[\begin{equation} \text{Valor-p} = Pr(Z \le z_{teste}). \tag{6.15} \end{equation}\]
Sob \(H_0: \mu \le \mu_0\), \[\begin{equation} \text{Valor-p} = Pr(Z \ge z_{teste}). \tag{6.16} \end{equation}\]
Exemplo 6.16 É desejado testar se a média de altura dos alunos da PUCRS pode ser considerada maior do que 167 cm. A hipótese é portanto unilateral superior na forma \(H_0: \mu \le 167\) vs \(H_1: \mu > 167\). Estudos anteriores indicam que a variável \(X\): ‘altura dos alunos da PUCRS’ tem distribuição normal de média desconhecida (motivo da realização do teste de hipóteses para \(\mu\)) e desvio padrão \(\sigma=14\), indicado por \(X \sim \mathcal{N}(\mu,14)\). De uma amostra aleatória com \(n=25\) pessoas obteve-se \(\bar{x}_{25}=172\). Assim, sob \(H_0\) a estatística do teste pode ser calculada da seguinte maneira: \[z_{teste} = \frac{172-167}{14/\sqrt{25}} \approx 1.786 \approx 1.79.\] Se utilizarmos \(\alpha=0.05\) (unilateral superior), \(z_{cr\acute{\imath}tico}=1.64\). Como a estatística de teste extrapola o valor crítico, i.e., \(1.79 > 1.64\), rejeita-se \(H_0\). \(\\\) Decisão Estatística: Rejeita-se \(H_0\) com \(\alpha=5\%\) pois \(1.79 > 1.64\). Conclusão Experimental: A amostra sugere que a média de altura dos alunos da PUCRS deve ser maior do que 167 cm. \(\\\)
Exemplo 6.17 No Exemplo 6.16 é possível calcular o valor p associado à estatística de teste \(z_{teste} \approx 1.79\). Por ser um teste unilateral superior, basta obter a probabilidade de encontrar um valor tão ou mais extremo que \(z_{teste}\) conforme Equação (6.15). Pela tabela de normal padrão (com precisão inferior à do computador) \[\text{Valor-p} = Pr(Z \ge 1.79) = 1-Pr(Z<1.79) = 1-0.9633 = 0.0367.\] Utilizando \(\alpha=0.05\) unilateral decide-se novamente pela rejeição de \(H_0\) uma vez que o valor p é inferior ao nível de significância, i.e., \(0.0367 < 0.05\). A decisão realizada desta maneira deve sempre ser a mesma quando compara-se a estatística do teste com o(s) valor(es) crítico(s). \(\\\) Decisão Estatística: Rejeita-se \(H_0\) com \(\alpha=5\%\) pois \(0.0367 < 0.05\). Conclusão Experimental: A amostra sugere que a média de altura dos alunos da PUCRS deve ser maior do que 167 cm. \(\\\)
# Definindo os valores indicados no enunciado
mu0 <- 167
n <- 25
x_bar <- 172
sigma <- 14
(zt <- (x_bar-mu0)/(sigma/sqrt(n))) # estatística do teste, note a maior precisão## [1] 1.785714curve(dnorm(x), -3, 3) # gráfico da normal padrão
abline(v = qnorm(.95), col = 'red') # valor crítico de ≈1.64
## [1] 0.037072776.3.9.2 Teste \(t\) para média de uma amostra
Hipótese avaliada
Uma amostra de \(n\) sujeitos (ou objetos) vem de uma população de média \(\mu\) igual a um valor especificado \(\mu_0\)?
Suposições
S1. A amostra foi selecionada aleatoriamente da população que representa.
S2. A distribuição dos dados na população que a amostra representa é normal.
Testes relacionados
TESTE 15??? - Teste dos postos sinalizados de Wilcoxon para uma amostra
Estatística do teste
Sob \(H_0: \mu = \mu_0\),
\[\begin{equation}
t_{teste}=\frac{\bar{x}-\mu_0}{s/\sqrt{n}} \sim \mathcal{t}(gl),
\tag{6.17}
\end{equation}\]
onde \(gl=n-1\) indica os graus de liberdade que definem a distribuição \(t\).
Valor-p
Sob \(H_0: \mu = \mu_0\),
\[\begin{equation}
\text{Valor-p} = 2Pr(T \le -|t_{teste}|).
\tag{6.18}
\end{equation}\]
Sob \(H_0: \mu \ge \mu_0\), \[\begin{equation} \text{Valor-p} = Pr(T \le t_{teste}). \tag{6.19} \end{equation}\]
Sob \(H_0: \mu \le \mu_0\), \[\begin{equation} \text{Valor-p} = Pr(T \ge t_{teste}). \tag{6.20} \end{equation}\]
Exemplo 6.19 É desejado testar se a média de altura dos alunos da PUCRS pode ser considerada maior do que 167 cm. O teste é portanto unilateral superior na forma \(H_0: \mu \le 167\) vs \(H_1: \mu > 167\). Estudos anteriores indicam que a variável \(X\): ‘altura dos alunos da PUCRS’ tem distribuição normal de média e desvio padrão desconhecidos, indicado por \(X \sim \mathcal{N}(\mu,\sigma)\). De uma amostra aleatória com \(n=25\) pessoas obteve-se \(\bar{x}_{25}=172\) e \(s_{25}=14\). Assim, sob \(H_0\) a estatística do teste pode ser calculada da seguinte maneira:
\[t_{teste} = \frac{172-167}{14/\sqrt{25}} \approx 1.786.\]
Se utilizarmos \(\alpha=0.05\) (unilateral superior), \(t_{cr\acute{\imath}tico}=1.711\), considerando \(gl=24\) graus de liberdade. Como a estatística de teste extrapola o valor crítico, i.e., \(1.786 > 1.711\), rejeita-se \(H_0\). \(\\\)
Decisão Estatística: Rejeita-se \(H_0\) com \(\alpha=5\%\) pois \(1.786 > 1.711\).
Conclusão Experimental: A amostra sugere que a média de altura dos alunos da PUCRS deve ser maior do que 167 cm. \(\\\)
Exemplo 6.20 No Exemplo 6.19 é possível obter um intervalo para o valor p associado à estatística de teste \(t_{teste} \approx 1.786\). Por ser um teste unilateral superior, deve-se obter a probabilidade de encontrar um valor tão ou mais extremo que \(t_{teste}\) conforme Equação (6.19). Pela tabela de \(t\) com \(gl=24\) graus de liberdade obtém-se \(Pr(t>1.711) = 0.05\) e \(Pr(t>2.064) = 0.025\). Dada a limitação de precisão da tabela \(t\), pode-se apenas concluir que \(0.025 < Pr(t>1.786) < 0.05\). Utilizando \(\alpha=0.05\) unilateral decide-se novamente pela rejeição de \(H_0\) uma vez que o valor p é inferior ao nível de significância, i.e., \(Pr(t>1.786) < 0.05\). A decisão realizada desta maneira deve sempre ser a mesma quando compara-se a estatística do teste com o(s) valor(es) crítico(s). \(\\\)
Decisão Estatística: Rejeita-se \(H_0\) com \(\alpha=5\%\) pois \(Pr(t>1.786) < 0.05\).
Conclusão Experimental: A amostra sugere que a média de altura dos alunos da PUCRS deve ser maior do que 167 cm. \(\\\)
# Definindo os valores indicados no enunciado
mu0 <- 167
n <- 25
x_bar <- 172
s <- 14
(tt <- (x_bar-mu0)/(s/sqrt(n))) # estatística do teste, note a maior precisão## [1] 1.785714curve(dt(x, df = n-1), -3, 3) # gráfico da t com gl=25-1=24
abline(v = qt(.95, df = n-1), col = 'red') # valor crítico de ≈1.711
## [1] 0.043394536.3.9.3 TESTE PU2 - Testes para proporção de uma amostra, binomial (exato) e normal (assintótico)
Hipótese avaliada
Em uma população composta de duas categorias, a proporção \(\pi\) de observações em uma das categorias é igual a um valor específico \(\pi_0\)?
Suposições
S1. Cada observação pode ser classificada em sucesso ou fracasso.
S2. Cada uma das \(n\) observações (condicionalmente) independentes é selecionada aleatoriamente de uma população.
S3. A probabilidade de sucesso \(\pi\) se mantém constante a cada observação.
Estatística do teste (assintótico)
Sob \(H_0: \pi = \pi_0\),
\[\begin{equation}
z_{teste}=\frac{p-\pi_0}{\sqrt{\pi_0 (1-\pi_0)/n}} \sim \mathcal{N}(0,1).
\tag{6.21}
\end{equation}\]
Valor-p (assintótico)
Sob \(H_0: \pi = \pi_0\),
\[\begin{equation}
\text{Valor-p} = 2Pr(Z \le -|z_{teste}|).
\tag{6.22}
\end{equation}\]
Sob \(H_0: \pi \ge \pi_0\), \[\begin{equation} \text{Valor-p} = Pr(Z \le z_{teste}). \tag{6.23} \end{equation}\]
Sob \(H_0: \pi \le \pi_0\), \[\begin{equation} \text{Valor-p} = Pr(Z \ge z_{teste}). \tag{6.24} \end{equation}\]
Valor-p (exato)
Seja \(X\) o número de sucessos em \(n\) ensaios de Bernoulli. Sob \(H_0: \pi = \pi_0\) ocorre que \(X \sim \mathcal{B}(n,\pi_0)\), se \(x>\frac{n}{2}\) e \(I = \{ 0,1,\ldots,n-x, x,\ldots,n \}\),
\[\begin{equation}
\text{Valor-p} = Pr(n-x \ge X \ge x | \pi = \pi_0) = \sum_{i \in I} {n \choose i} \pi_{0}^i (1-\pi_0)^{n-i},
\tag{6.25}
\end{equation}\]
se \(x<\frac{n}{2}\) e \(I = \{ 0,1,\ldots,x, n-x,\ldots,n \}\), \[\begin{equation} \text{Valor-p} = Pr(x \ge X \ge n-x | \pi = \pi_0) = \sum_{i \in I} {n \choose i} \pi_{0}^i (1-\pi_0)^{n-i}, \tag{6.26} \end{equation}\]
e \(\text{Valor-p} = 1\) se \(x=\frac{n}{2}\).
Sob \(H_0: \pi \le \pi_0\), \[\begin{equation} \text{Valor-p} = Pr(X \ge x | \pi = \pi_0) = \sum_{i=x}^{n} {n \choose i} \pi_{0}^i (1-\pi_0)^{n-i} \tag{6.27} \end{equation}\]
Sob \(H_0: \pi \ge \pi_0\), \[\begin{equation} \text{Valor-p} = Pr(X \le x | \pi = \pi_0) = \sum_{i=0}^{x} {n \choose i} \pi_{0}^i (1-\pi_0)^{n-i} \tag{6.28} \end{equation}\]
Exemplo 6.22 Suponha que deseja-se testar \(\pi\), a proporção de caras em uma moeda, na forma \(H_0: \pi \le 0.5\) vs \(H_1 : \pi > 0.5\). Para isso a moeda é lançada \(n=12\) vezes, onde se observam \(x=9\) caras e \(n-x=12-9=3\) coroas. Sabe-se que \(p=\frac{9}{12}=\frac{3}{4}=0.75\). Considerando a abordagem assintótica, sob \(H_0\) \[z_{teste}=\frac{0.75-0.5}{\sqrt{0.5 (1-0.5)/12}} \approx 1.73.\] Se utilizarmos \(\alpha=0.05\) (unilateral superior), \(z_{cr\acute{\imath}tico}=1.64\). Como a estatística de teste extrapola o valor crítico, i.e., \(1.73 > 1.64\), rejeita-se \(H_0\). \(\\\) Decisão Estatística: Rejeita-se \(H_0\) com \(\alpha=5\%\) pois \(1.73 > 1.64\). Conclusão Experimental: A amostra sugere que a proporção de caras da moeda deve ser considerada maior que 0.5. \(\\\)
Exemplo 6.23 Considere novamente os dados do Exemplo 6.22. Pela Equação (6.16) utilizando a tabela de normal padrão (com precisão inferior à do computador), \[\text{Valor-p} = Pr(Z \ge 1.73) = 1-Pr(Z<1.73) = 1-0.9582 = 0.0418.\] Utilizando \(\alpha=0.05\) unilateral decide-se novamente pela rejeição de \(H_0\) uma vez que o valor p é inferior ao nível de significância, i.e., \(0.0418 < 0.05\). A decisão realizada desta maneira deve sempre ser a mesma quando compara-se a estatística do teste com o(s) valor(es) crítico(s). \(\\\) Decisão Estatística: Rejeita-se \(H_0\) com \(\alpha=5\%\) pois \(0.0418 < 0.05\). Conclusão Experimental: A amostra sugere que a proporção de caras da moeda deve ser considerada maior que 0.5. \(\\\)
## [1] 0.75## [1] 1.732051## [1] 0.04163226# usando a função prop.test, sem a correção de Yates
prop.test(x, n, pi0, alternative = 'greater', correct = FALSE)##
## 1-sample proportions test without continuity correction
##
## data: x out of n, null probability pi0
## X-squared = 3, df = 1, p-value = 0.04163
## alternative hypothesis: true p is greater than 0.5
## 95 percent confidence interval:
## 0.512662 1.000000
## sample estimates:
## p
## 0.75Exemplo 6.25 Considere novamente os dados do Exemplo 6.22. O teste exato pode ser realizado considerando que sob \(H_0: \pi \le 0.5\), o número de caras (sucessos) \(X\) tem distribuição binomial de parâmetros \(n=12\) e \(\pi=0.5\), i.e., \(X \sim \mathcal{B}(12,0.5)\). Assim, o valor-p exato resulta em \[\begin{equation} Pr\left( X \geq 9 | \pi = 0.5 \right) = \left[ \binom {12}{9} + \binom {12}{10} + \binom {12}{11} + \binom {12}{12} \right] \times 0.5^{12} \approx 0.0730. \nonumber \end{equation}\] Note a diferença do valor exato em comparação ao assintótico. Decisão Estatística: não se rejeita \(H_0\) com \(\alpha=5\%\) pois \(0.0730 > 0.05\). Conclusão Experimental: a amostra sugere que a proporção de caras da moeda pode ser considerada menor ou igual a 0.5. \(\\\)
Exemplo 6.26 Realizando o Exemplo 6.25 no R.
# manualmente
n <- 12
x <- 9
pi0 <- 0.5
p9 <- dbinom(9,n,pi0)
p10 <- dbinom(10,n,pi0)
p11 <- dbinom(11,n,pi0)
p12 <- dbinom(12,n,pi0)
p9+p10+p11+p12 # valor-p## [1] 0.07299805##
## Exact binomial test
##
## data: x and n
## number of successes = 9, number of trials = 12, p-value = 0.073
## alternative hypothesis: true probability of success is greater than 0.5
## 95 percent confidence interval:
## 0.4726734 1.0000000
## sample estimates:
## probability of success
## 0.75# usando a função prop.test (assintótico mas com correção de continuidade de Yates)
prop.test(x, n, pi0, alternative = 'greater')##
## 1-sample proportions test with continuity correction
##
## data: x out of n, null probability pi0
## X-squared = 2.0833, df = 1, p-value = 0.07446
## alternative hypothesis: true p is greater than 0.5
## 95 percent confidence interval:
## 0.4713103 1.0000000
## sample estimates:
## p
## 0.75Exercício 6.13 Refaça os Exemplos 6.22, 6.23 e 6.25 considerando \(H_0: \pi = 0.6\) vs \(H_1 : \pi \ne 0.6\). \(\\\)
Exercício 6.14 Uma rádio do estado anunciou que 90% dos hotéis da Serra Gaúcha estariam lotados no final de semana do dia dos pais. A estação aconselhou os ouvintes a fazerem reserva antecipada para se hospedar na Serra nestes dias. No sábado à noite uma amostra de 58 hotéis revelou que 49 diziam ‘sem vagas’. Qual é a sua reação à afirmação da rádio, depois de ver a evidência da amostra? Use 5% de nível de significância. \(\\\)
Exercício 6.15 Você é responsável por avaliar a qualidade de um grande lote de peças de segunda mão adquiridas pela sua empresa. O fabricante afirma haver no máximo 10% de peças defeituosas, e você decide investigar. Para isso você retira uma amostra de 50 peças, das quais 9 são defeituosas. Qual a sua opinião sobre o lote adquirido, considerando níveis de significância de 1%, 5% e 10%? Defina as hipóteses, apresentando a Decisão Estatística e a Conclusão Experimental. \(\\\)
6.3.9.4 TESTE PU3 - Teste qui-quadrado para a variância populacional de uma amostra
Hipótese avaliada Uma amostra de \(n\) sujeitos (ou objetos) vem de uma população na qual a variância \(\sigma^2\) é igual a um valor especificado \(\sigma_0^2\)?
Suposições
S1. A amostra foi selecionada aleatoriamente da população que representa.
S2. A distribuição dos dados na população que a amostra representa é normal.
Estatística do teste Sob \(H_0: \sigma^2 = \sigma_0^2\), \[\begin{equation} \chi_{teste}^2=\frac{(n-1)s^2}{\sigma_0^2} \sim \mathcal{\chi}^2(gl), \tag{6.29} \end{equation}\]
onde \(gl=n-1\) indica os graus de liberdade que definem a distribuição \(\chi^2\).
Valor-p Sob \(H_0: \sigma^2 = \sigma_0^2\), \[\begin{equation} \text{Valor-p} = 2Pr(\chi^2 \le \chi_{teste}^2). \tag{6.30} \end{equation}\]
Sob \(H_0: \sigma^2 \ge \sigma_0^2\), \[\begin{equation} \text{Valor-p} = Pr(\chi^2 \le \chi_{teste}^2). \tag{6.31} \end{equation}\]
Sob \(H_0: \sigma^2 \le \sigma_0^2\), \[\begin{equation} \text{Valor-p} = Pr(\chi^2 \ge \chi_{teste}^2). \tag{6.32} \end{equation}\]
Exemplo 6.27 Deseja-se testar se a variância de uma variável com distribuição normal pode ser considerada igual a 5, i.e., \(H_0: \sigma^2 = 5\) vs \(H_0: \sigma^2 \ne 5\). Para isso observa-se uma amostra de tamanho \(n=41\), de onde se calcula uma variância amostral de \(s^2 \approx 3.196876\). Sob \(H_0\) \[\chi_{teste}^2=\frac{(41-1) \times 3.196876 }{5} \approx 25.58.\] Considerando \(\alpha=0.05\) (bilateral) e a tabela qui-quadrado com \(gl=41-1=40\), \(\chi_{cr\acute{\imath}tico1}^2=24.43\) e \(\chi_{cr\acute{\imath}tico2}^2=59.34\). Como a estatística de teste não extrapola os valores críticos, i.e., \(24.43 < 25.58 < 59.34\), não se rejeita \(H_0\). \(\\\) Decisão Estatística: Não se rejeita \(H_0\) com \(\alpha=0.05\) pois \(24.43 < 25.58 < 59.34\). Conclusão Experimental: A amostra sugere que a variância da referida variável pode ser considerada igual a 5. \(\\\)
Exemplo 6.28 Realizando o Exemplo 6.27 no R.
# Definindo os valores indicados no enunciado
sigma2_0 <- 5
n <- 41
set.seed(123); x <- rnorm(n, mean = 0, sd = 2)
(s2 <- var(x))## [1] 3.196876## [1] 25.57501curve(dchisq(x, df = n-1), 0, 80) # gráfico da qui^2 com gl=41-1=40
(qui_cr1 <- qchisq(.025, df = n-1)) # valor crítico 1## [1] 24.43304## [1] 59.34171
## [1] 0.07434994## [1] 0.03717497## [1] 0.962825# Via pacote DescTools
library(DescTools)
VarTest(x, sigma.squared = sigma2_0, alternative = 'two.sided')##
## One Sample Chi-Square test on variance
##
## data: x
## X-squared = 25.575, df = 40, p-value = 0.1069
## alternative hypothesis: true variance is not equal to 5
## 95 percent confidence interval:
## 2.154893 5.233694
## sample estimates:
## variance of x
## 3.196876##
## One Sample Chi-Square test on variance
##
## data: x
## X-squared = 25.575, df = 40, p-value = 0.03717
## alternative hypothesis: true variance is less than 5
## 95 percent confidence interval:
## 0.00000 4.82378
## sample estimates:
## variance of x
## 3.196876##
## One Sample Chi-Square test on variance
##
## data: x
## X-squared = 25.575, df = 40, p-value = 0.9628
## alternative hypothesis: true variance is greater than 5
## 95 percent confidence interval:
## 2.293374 Inf
## sample estimates:
## variance of x
## 3.196876Exercício 6.16 Suponha que o comprimento de peças em uma fábrica, simbolizado por \(X\), tenha distribuição normal de média e variância desconhecidas, anotado por \(X \sim \mathcal{N}(\mu,\sigma)\). A especificação indica média de 140cm, e desvio padrão de 7cm. Se em uma amostra de 64 peças foi observada uma média de \(\bar{x}=138\)cm e um desvio padrão de \(s=12\)cm, realize os testes de hipóteses apropriados para avaliar se as especificações estão sendo cumpridas. \(\\\)
6.3.9.5 TESTE PU4 - Teste qui-quadrado de aderência de uma amostra
Hipótese avaliada No universo representado por uma amostra, há diferença entre as frequências esperadas e observadas?
Suposições
S1. Os dados avaliados consistem em uma amostra aleatória de \(n\) observações (condicionalmente) independentes.
S2. Os dados representam frequências de \(k\) categorias mutuamente exclusivas.
Estatística do teste Sob \(H_0: \pi_1=\pi_1^0, \pi_2=\pi_2^0, \ldots, \pi_k=\pi_k^0\), \[\begin{equation} \chi_{teste}^2 = \sum_{i=1}^{k} \frac{(O_{i}-E_{i})^2}{E_{i}} \sim \chi^2(gl), \tag{6.33} \end{equation}\]
onde \(E_{i}=n\pi_i^0\), \(k\) é o número de categorias e \(gl=k-1\) indica os graus de liberdade que definem a distribuição \(\chi^2\).
Valor-p Sob \(H_0: \pi_1=\pi_1^0, \pi_2=\pi_2^0, \ldots, \pi_k=\pi_k^0\), \[\begin{equation} \text{Valor-p} = Pr(\chi^2 \ge \chi_{teste}^2). \tag{6.34} \end{equation}\]
Exemplo 6.29 (Adaptado de (Sheskin 2011, 278) - Teste qui-quadrado de aderência balanceado) Um dado é lançado 120 vezes, a fim de determinar se pode ou não ser considerado equilibrado. Os valores observados estão apresentados conforme tabela abaixo, e \(E_i=120 \times \frac{1}{6}=20, i \in \{1,2,3,4,5,6\}\).
| Face (\(i\)) | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| \(O_{i}\) | 20 | 14 | 18 | 17 | 22 | 29 |
| \(E_{i}\) | 20 | 20 | 20 | 20 | 20 | 20 |
Sob \(H_0: \pi_1=\frac{1}{6}, \pi_2=\frac{1}{6}, \pi_3=\frac{1}{6}, \pi_4=\frac{1}{6}, \pi_5=\frac{1}{6}, \pi_6=\frac{1}{6}\), \[\chi_{teste}^2 = \frac{(20-20)^2}{20} + \frac{(14-20)^2}{20} + \frac{(18-20)^2}{20} + \frac{(17-20)^2}{20} + \frac{(22-20)^2}{20} + \frac{(29-20)^2}{20} = 6.7.\] Considerando \(\alpha=0.05\) (unilateral superior, que é sempre o caso deste teste) e a tabela qui-quadrado com \(gl=6-1=5\), \(\chi_{cr\acute{\imath}tico}^2=11.07\). Como a estatística de teste não extrapola os valores críticos, i.e., \(6.7 < 11.07\), não se rejeita \(H_0\). Considerando a Equação (6.34) e a função pchisq, \[\text{Valor-p} = Pr(\chi^2 \ge 6.7) \approx 0.2439.\]
Decisão Estatística: Não se rejeita \(H_0\) com \(\alpha=0.05\) pois \(6.7 < 11.07\) ou \(0.2439 > 0.05\).
Conclusão Experimental: A amostra sugere que o dado deve ser equilibrado. \(\\\)
curve(dchisq(x, df=5), 0, 20) # gráfico da qui^2 com gl=6-1=5
(qui_cr <- qchisq(.95, df=5)) # valor crítico## [1] 11.0705
o <- c(20,14,18,17,22,29) # Observados
n <- sum(o) # Tamanho da amostra
p <- rep(1/6,6) # Distribuição uniforme (dado equilibriado)
e <- n*p # Valores esperados se o dado for equilibrado
k <- length(o) # Número de categorias
(qui <- sum((o-e)^2/e)) # Equação (3.25)## [1] 6.7## [1] 0.2439246##
## Chi-squared test for given probabilities
##
## data: o
## X-squared = 6.7, df = 5, p-value = 0.2439Exemplo 6.30 (Teste qui-quadrado de aderência desbalanceado) Gregor Mendel conduziu experimentos sobre hereditariedade em ervilhas. Em suma, as ervilhas podiam ser redondas (R) ou enrugadas (E), amarelas (A) ou verdes (V). Portanto, existem quatro combinações possíveis: RA, RV, EA, EV. Se sua teoria estivesse correta, as ervilhas seriam observadas na proporção de 9:3:3:1. Se o resultado do experimento produziu os seguintes dados observados, pode-se avaliar se há indícios da proporção considerada29.
| \(i\) | RA (1) | RV (2) | EA (3) | EV (4) | \(n\) |
|---|---|---|---|---|---|
| \(O_i\) | 315 | 108 | 101 | 32 | 556 |
| \(E_i\) | 312.75 | 104.25 | 104.25 | 34.75 | 556 |
Sob \(H_0: \pi_1=\frac{9}{16}, \pi_2=\frac{3}{16}, \pi_3=\frac{3}{16}, \pi_4=\frac{1}{16}\), \[\chi_{teste}^2 = \frac{(315-312.75)^2}{312.75} + \frac{(108-104.25)^2}{104.25} + \frac{(101-104.25)^2}{104.25} + \frac{(32-34.75)^2}{34.75} \approx 0.47.\] Considerando \(\alpha=0.05\) (unilateral superior, que é sempre o caso deste teste) e a tabela qui-quadrado com \(gl=4-1=3\), \(\chi_{cr\acute{\imath}tico}^2=7.81\). Como a estatística de teste não extrapola os valores críticos, i.e., \(0.47 < 7.81\), não se rejeita \(H_0\). Considerando a Equação (6.34) e a função pchisq, \[\text{Valor-p} = Pr(\chi^2 \ge 0.47) \approx 0.9254.\]
Decisão Estatística: Não se rejeita \(H_0\) com \(\alpha=0.05\) pois \(0.47 < 7.81\) ou \(0.9254 > 0.05\).
Conclusão Experimental: A amostra sugere que a proporção das ervilhas deve ser 9:3:3:1. \(\\\)
## [1] 556## [1] 4p <- c(9/16,3/16,3/16,1/16) # Proporção 9:3:3:1
(e <- n*p) # Valores esperados se a prop. for 9:3:3:1## [1] 312.75 104.25 104.25 34.75## [1] 0.470024## [1] 0.9254259##
## Chi-squared test for given probabilities
##
## data: o
## X-squared = 0.47002, df = 3, p-value = 0.92546.3.10 Paramétricos Bivariados
6.3.10.1 TESTE PB1 - Teste F (de Hartley) de igualdade de variâncias
Hipótese avaliada A variância do universo 1 é igual à variância do universo 2.
Suposições S1. Os tamanhos de amostra \(n1\) e \(n2\) são similares.
Estatística do teste Sob \(H_0: \sigma_1=\sigma_2\), \[\begin{equation} F_{max}=\frac{s_{max}^2}{s_{min}^2} \sim \mathcal{F}(n_{max}-1,n_{min}-1), \tag{6.35} \end{equation}\]
onde \(s_{max}^2\) e \(s_{min}^2\) são respectivamente a maior e menor variância amostral, e \(n_{max}\) e \(n_{min}\) correspondem respectivamente ao tamanho de amostra associado à amostra de maior e menor variância.
Valor-p Sob \(H_0: \sigma_1=\sigma_2\), \[\begin{equation} \text{Valor-p} = 2Pr(F \ge F_{max}). \tag{6.36} \end{equation}\]
Sob \(H_0: \sigma_1 \ge \sigma_2\), \[\begin{equation} \text{Valor-p} = Pr(F \ge F_{max}). \tag{6.37} \end{equation}\]
Sob \(H_0: \sigma_1 \le \sigma_2\), \[\begin{equation} \text{Valor-p} = Pr(F < F_{max}). \tag{6.38} \end{equation}\]
## [1] 1.909091## [1] 0.3342733## [1] 0.1671366## [1] 0.8328634##
## F test to compare two variances
##
## data: x and y
## F = 0.52381, num df = 9, denom df = 13, p-value = 0.3343
## alternative hypothesis: true ratio of variances is not equal to 1
## 95 percent confidence interval:
## 0.1581535 2.0065024
## sample estimates:
## ratio of variances
## 0.5238095##
## F test to compare two variances
##
## data: x and y
## F = 0.52381, num df = 9, denom df = 13, p-value = 0.1671
## alternative hypothesis: true ratio of variances is less than 1
## 95 percent confidence interval:
## 0.000000 1.596335
## sample estimates:
## ratio of variances
## 0.5238095##
## F test to compare two variances
##
## data: x and y
## F = 0.52381, num df = 9, denom df = 13, p-value = 0.8329
## alternative hypothesis: true ratio of variances is greater than 1
## 95 percent confidence interval:
## 0.1929775 Inf
## sample estimates:
## ratio of variances
## 0.52380956.3.10.2 TESTE PB2 - Teste \(t\) para médias de duas amostras independentes
Hipótese avaliada Duas amostras independentes representam duas populações com valores médios diferentes?
Suposições
S1. Cada amostra foi selecionada aleatoriamente da população que representa.
S2. A distribuição dos dados na população subjacente de cada amostra é normal.
Testes relacionados TESTE 18??? - Teste dos postos de Mann-Whitney para amostras independentes
Estatística do teste Sob \(H_0: \mu_1-\mu_2 = \Delta_0\) e \(\sigma_1 = \sigma_2\), \[\begin{equation} t_{teste} = \frac{(\bar{x}_1-\bar{x}_2) - \Delta_0}{\sqrt{\left[ \frac{(n_1-1)s_1^2 + (n_2-1)s_2^2}{n_1+n_2-2} \right] \left[ \frac{1}{n_1}+\frac{1}{n_2} \right]}} \sim \mathcal{t}(gl). \tag{6.39} \end{equation}\]
Sob \(H_0: \mu_1-\mu_2 = \Delta_0\) e \(\sigma_1 \ne \sigma_2\), \[\begin{equation} t_{teste} = \frac{(\bar{x}_1-\bar{x}_2) - \Delta_0}{\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}} \sim \mathcal{t}(gl), \tag{6.40} \end{equation}\]
onde \(n_1\) e \(n_2\) são os tamanhos das amostras, \(\bar{x}_1\) e \(\bar{x}_2\) representam as médias amostrais e \(s_1^2\) e \(s_2^2\) são as variâncias amostrais dos universos 1 e 2. Se as variâncias forem admitidas iguais (\(\sigma_1 = \sigma_2\)), os graus de liberdade são calculados utilizando a expressão \[\begin{equation} gl = n_1 + n_2-2. \tag{6.41} \end{equation}\] No caso de as variâncias serem admitidas diferentes (\(\sigma_1 \ne \sigma_2\)), calculam-se os graus de liberdade com a abordagem de (Welch 1938), dados por \[\begin{equation} gl = \frac{\left( \frac{s_1^2}{n_1} + \frac{s_2^2}{n_2} \right)^2}{ \frac{(s_1^2/n_1)^2}{n_1-1} + \frac{(s_2^2/n_2)^2}{n_2-1}}. \tag{6.42} \end{equation}\]
Valor-p Sob \(H_0: \mu_1-\mu_2 = \Delta_0\), \[\begin{equation} \text{Valor-p} = 2Pr(t \le -|t_{teste}|). \tag{6.43} \end{equation}\]
Sob \(H_0: \mu_1-\mu_2 \ge \Delta_0\), \[\begin{equation} \text{Valor-p} = Pr(t \le t_{teste}). \tag{6.44} \end{equation}\]
Sob \(H_0: \mu_1-\mu_2 \le \Delta_0\), \[\begin{equation} \text{Valor-p} = Pr(t \ge t_{teste}). \tag{6.45} \end{equation}\]
Exemplo 6.31 \(\\\)
6.3.10.3 TESTE PB3 - Teste \(t\) para médias de duas amostras dependentes/pareadas
Hipótese avaliada Duas amostras dependentes representam duas populações com médias diferentes?
Suposições
S1. Cada amostra foi selecionada aleatoriamente da população que representa.
S2. A distribuição dos dados na população subjacente de cada amostra é normal.
S3. (Homogeneidade de variâncias) A variância da população representada pela amostra 1 é igual à variância da população representada pela amostra 2 (\(\sigma_1^2=\sigma_2^2\)).
Testes relacionados TESTE 19??? - Teste dos postos de Wilcoxon para amostras dependentes/pareadas.
Estatística do teste Sob \(H_0: \mu_1-\mu_2 = \Delta_0\), \[\begin{equation} t_{teste} = \frac{\bar{D}-\Delta_0}{s_{\bar{D}}/\sqrt{n}} \sim \mathcal{t}(gl), \tag{6.46} \end{equation}\]
onde \[\bar{D} = \frac{\sum D}{n},\] \(D=x_1-x_2\) e \[\begin{equation} s_{\bar{D}} = \sqrt{\left( \frac{\sum D^2}{n} - \bar{D}^2 \right) \left( \frac{n}{n-1} \right)}. \tag{6.47} \end{equation}\]
Valor-p Sob \(H_0: \mu_1-\mu_2 = \Delta_0\), \[\begin{equation} \text{Valor-p} = 2Pr(t \le -|t_{teste}|). \tag{6.48} \end{equation}\]
Sob \(H_0: \mu_1-\mu_2 \ge \Delta_0\), \[\begin{equation} \text{Valor-p} = Pr(t \le t_{teste}). \tag{6.49} \end{equation}\]
Sob \(H_0: \mu_1-\mu_2 \le \Delta_0\), \[\begin{equation} \text{Valor-p} = Pr(t \ge t_{teste}). \tag{6.50} \end{equation}\]
Exemplo 6.32 Adaptado de (Sheskin 2011, 764).
# dados
x1 <- c(9,2,1,4,6,4,7,8,5,1)
x2 <- c(8,2,3,2,3,0,4,5,4,0)
# validando suposições
shapiro.test(x1) # S2, normalidade##
## Shapiro-Wilk normality test
##
## data: x1
## W = 0.94398, p-value = 0.5981##
## Shapiro-Wilk normality test
##
## data: x2
## W = 0.93776, p-value = 0.5284g <- as.factor(rep(1:2, each = length(x1))) # grupos 1 e 2
car::leveneTest(c(x1,x2),g) # S3, homogeneidade de variâncias## Levene's Test for Homogeneity of Variance (center = median)
## Df F value Pr(>F)
## group 1 0.777 0.3897
## 18## [1] 1.6## [1] 1.776388## [1] 2.848276## [1] 0.01914294##
## Paired t-test
##
## data: x1 and x2
## t = 2.8483, df = 9, p-value = 0.01914
## alternative hypothesis: true mean difference is not equal to 0
## 95 percent confidence interval:
## 0.3292483 2.8707517
## sample estimates:
## mean difference
## 1.6Exercício 6.17 Faça o Exemplo 6.32 considerando \(H_0: \mu_1-\mu_2 \ge 0\) e \(H_0: \mu_1-\mu_2 \ge 0\).
6.3.10.4 TESTE PB4 - Teste \(z\) para duas proporções independentes
Hipótese avaliada Nas populações subjacentes que as amostras representam, a proporção de observações na linha 1 (condição de ruído) que cai na célula \(a\) é igual à proporção de observações na linha 2 (condição sem ruído) que cai na célula \(c\).
Suposições
Testes relacionados TESTE 12??? - Testes qui-quadrado para tabelas \(l \times c\). TESTE 13??? - Teste exato de Fisher para tabelas \(2 \times 2\)
Estatística do teste
Sob \(H_0: \pi_1-\pi_2 = 0\),
Sem correção de Yates \[\begin{equation} z = \dfrac{|p_{1} - p_{2}|}{\sqrt{\bar{p} (1-\bar{p}) \left( \dfrac{1}{n_1} + \dfrac{1}{n_2} \right) } } \sim \mathcal{N}(0,1), \tag{6.51} \end{equation}\]
\[\begin{equation} \chi^2 = z^2 \sim \mathcal{\chi}^2_1, \tag{6.52} \end{equation}\]
Com correção de Yates \[\begin{equation} z_{Yates} = \dfrac{|p_{1} - p_{2}| - \frac{1}{2} \left( \frac{1}{n_1} + \frac{1}{n_2} \right)}{\sqrt{\bar{p} (1-\bar{p}) \left( \frac{1}{n_1} + \frac{1}{n_2} \right) } } \sim \mathcal{N}(0,1), \tag{6.53} \end{equation}\]
\[\begin{equation} \chi^2_{Yates} = z_{Yates}^2 \sim \mathcal{\chi}^2_1, \tag{6.54} \end{equation}\]
\(p_1 = \frac{x_1}{n_1}\), \(p_2 = \frac{x_2}{n_2}\), \(\bar{p} = \frac{x_1 + x_2}{n_1+n_2}\) onde \(n_1\) e \(n_2\) são os tamanhos das amostras retiradas de dois universos, \(x_1\) e \(x_2\) representam o número de observações pertencentes aos universos 1 e 2.
Valor-p
Exemplo 6.33 .
x1 <- 1568
n1 <- 1568+4066
p1 <- x1/n1
x2 <- 6257
n2 <- 6257+13639
p2 <- x2/n2
pb <- (x1+x2)/(n1+n2)
(z <- (p1-p2)/sqrt(pb*(1-pb)*(1/n1+1/n2)))## [1] -5.199192## [1] 27.0316##
## 2-sample test for equality of proportions with continuity correction
##
## data: c(x1, x2) out of c(n1, n2)
## X-squared = 26.862, df = 1, p-value = 1.093e-07
## alternative hypothesis: less
## 95 percent confidence interval:
## -1.00000000 -0.02484649
## sample estimates:
## prop 1 prop 2
## 0.2783103 0.31448536.3.10.5 TESTE 11 - Teste binomial para proporções de duas amostras dependentes
p. 823 Hipótese avaliada Duas amostras independentes representam duas populações com diferentes proporções?
Suposições S1. A amostra de n sujeitos foi selecionada aleatoriamente da população S2. O formato dos dados é tal que dentro de cada par de pontuações as duas pontuações podem ser ordenadas por classificação
\(\pi+\): Proporção de indivíduos que obtêm uma diferença com sinal positivo (ou seja, uma pontuação mais alta na condição 1 do que na condição 2) é igual a 0,5.)
Valor-p (exato) Seja \(X\) o número de sucessos em \(n\) ensaios de Bernoulli. Sob \(H_0: \pi+ = \pi_0\) ocorre que \(X \sim \mathcal{B}(n,\pi_0)\), se \(x>\frac{n}{2}\) e \(I = \{ 0,1,\ldots,n-x, x,\ldots,n \}\), \[\begin{equation} \text{Valor-p} = Pr(n-x \ge X \ge x | \pi+ = \pi_0) = \sum_{i \in I} {n \choose i} \pi_{0}^i (1-\pi+_0)^{n-i}, \tag{6.55} \end{equation}\]
se \(x<\frac{n}{2}\) e \(I = \{ 0,1,\ldots,x, n-x,\ldots,n \}\), \[\begin{equation} \text{Valor-p} = Pr(x \ge X \ge n-x | \pi+ = \pi_0) = \sum_{i \in I} {n \choose i} \pi_{0}^i (1-\pi_0)^{n-i}, \tag{6.56} \end{equation}\]
e \(\text{Valor-p} = 1\) se \(x=\frac{n}{2}\).
Sob \(H_0: \pi+ \le \pi_0\), \[\begin{equation} \text{Valor-p} = Pr(X \ge x | \pi = \pi_0) = \sum_{i=x}^{n} {n \choose i} \pi_{0}^i (1-\pi_0)^{n-i} \tag{6.57} \end{equation}\]
Sob \(H_0: \pi+ \ge \pi_0\), \[\begin{equation} \text{Valor-p} = Pr(X \le x | \pi = \pi_0) = \sum_{i=0}^{x} {n \choose i} \pi_{0}^i (1-\pi_0)^{n-i} \tag{6.58} \end{equation}\]
Valor-p (assintótico) Sob \(H_0: \pi+ = \pi_0\), vide Equação (6.14).
Sob \(H_0: \pi+ \ge \pi_0\), vide Equação (6.15).
Sob \(H_0: \pi+ \le \pi_0\), vide Equação (6.16).
Estatística do teste (assintótico) Sob \(H_0: \pi+ = \pi_0\), \[\begin{equation} z_{teste}=\frac{p-\pi_0}{\sqrt{\pi_0 (1-\pi_0)/n}} \sim \mathcal{N}(0,1). \tag{6.59} \end{equation}\]
Valor-p ::: {.example #binom-duas-prop-dep} . :::
##
## Exact binomial test
##
## data: c(682, 243)
## number of successes = 682, number of trials = 925, p-value = 0.3825
## alternative hypothesis: true probability of success is not equal to 0.75
## 95 percent confidence interval:
## 0.7076683 0.7654066
## sample estimates:
## probability of success
## 0.73729736.3.10.6 TESTE 12 - Testes qui-quadrado para tabelas \(l \times c\)
Estes testes são extensões do teste qui-quadrado de aderência de uma amostra (TESTE 5).
Hipótese avaliada (geral) Na(s) população(ões) representada(s) pela(s) amostra(s) em uma tabela de contingência, as frequências de células observadas são diferentes das frequências esperadas?
Hipóteses avaliadas (homogeneidade) As \(l\) amostras são ou não homogêneas com relação à proporção de observações em cada uma das \(c\) categorias? (ou) Se os dados forem homogêneos, a proporção de observações na \(j\)-ésima categoria será igual em todas as \(l\) populações?
Hipótese avaliada (independência) As duas dimensões/variáveis são independentes uma da outra?
Suposições
S1. Os dados avaliados representam uma amostra aleatória composta por \(n\) observações independentes.
S2. Os dados de frequência são categóricos para \(l \times c\) categorias mutuamente exclusivas.
S3. A frequência esperada de cada célula da tabela de contingência é de pelo menos 5.
S4. (Homogeneidade) As somas das linhas e colunas (somas marginais) são predeterminadas/fixas.
S4. (Independência) As somas das linhas e colunas (somas marginais) não são predeterminadas/fixas.
Testes relacionados
No caso de \(l>2\) ou \(c>2\) pode-se considerar uma análise post hoc30 para o teste qui-quadrado de Pearson para dados de contagem, proposta por (Beasley and Schumacker 1995), disponível no pacote chisq.posthoc.test (Ebbert 2019).
Estatística do teste (sem correção de Yates) Sob \(H_0: O_{ij}=E_{ij}\) para todas as células ou \(H_0: \pi_{ij}=(\pi_{i\cdot})(\pi_{\cdot j})\) para todas as \(l \times c\) células, \[\begin{equation} \chi_{teste}^2 = \sum_{i=1}^{l} \sum_{j=1}^{c} \frac{(O_{ij}-E_{ij})^2}{E_{ij}} \sim \chi^2(gl), \tag{6.60} \end{equation}\] onde \[\begin{equation} E_{ij}=\frac{(O_{i \cdot})(O_{\cdot j})}{n}. \tag{6.61} \end{equation}\] \(k\) é o número de categorias e \(gl=(l-1)(c-1)\) indica os graus de liberdade que definem a distribuição \(\chi^2\).
Estatística do teste (com correção de Yates) Sob \(H_0: O_{ij}=E_{ij}\) para todas as células ou \(H_0: \pi_{ij}=(\pi_{i\cdot})(\pi_{\cdot j})\) para todas as \(l \times c\) células, \[\begin{equation} \chi_{teste}^2 = \sum_{i=1}^{l} \sum_{j=1}^{c} \frac{(|O_{ij}-E_{ij}|-0.5)^2}{E_{ij}} \sim \chi^2(gl), \tag{6.62} \end{equation}\]
Estatística do teste simplificada para tabelas \(2 \times 2\) (sem correção de Yates) Sob \(H_0: O_{ij}=E_{ij}\) para todas as células ou \(H_0: \pi_{ij}=(\pi_{i\cdot})(\pi_{\cdot j})\) para todas as \(l \times c\) células, \[\begin{equation} \chi_{teste}^2 = \frac{n(ad-bc)^2}{(a+b)(c+d)(a+c)(b+d)}, \tag{6.63} \end{equation}\] onde \(a\), \(b\), \(c\) e \(d\) são as quantidades conforme tabela a seguir.
| Coluna 1 | Coluna 2 | Total | |
|---|---|---|---|
| Linha 1 | \(a\) | \(b\) | a+b |
| Linha 2 | \(c\) | \(d\) | c+d |
| Total | \(a+c\) | \(b+d\) | n |
Estatística do teste simplificada para tabelas \(2 \times 2\) (com correção de Yates) Sob \(H_0: O_{ij}=E_{ij}\) para todas as células ou \(H_0: \pi_{ij}=(\pi_{i\cdot})(\pi_{\cdot j})\) para todas as \(l \times c\) células, \[\begin{equation} \chi_{teste}^2 = \frac{n(|ad-bc|-0.5n)^2}{(a+b)(c+d)(a+c)(b+d)}. \tag{6.64} \end{equation}\]
Exemplo 6.34 (Adaptado de (Sheskin 2011, 639), teste de homogeneidade) Um pesquisador realiza um estudo para avaliar o efeito do ruído no comportamento altruísta. Cada um dos 200 sujeitos que participam do experimento é atribuído aleatoriamente a uma de duas condições experimentais. Os indivíduos em ambas as condições realizam um teste de uma hora, que é ostensivamente uma medida de inteligência. Durante o teste, os 100 indivíduos do Grupo 1 são expostos a um ruído alto e contínuo, que, segundo eles, é devido a um gerador com defeito. Os 100 sujeitos do Grupo 2 não são expostos a nenhum ruído durante o teste. Após a conclusão desta etapa do experimento, cada sujeito, ao deixar a sala, é confrontado por um homem de meia-idade cujo braço está em uma tipóia e que trabalha no experimentado. O homem pergunta ao sujeito se estaria disposto a ajudá-lo a carregar um pacote pesado para o carro. O número de sujeitos em cada grupo que ajudam o homem é registrado. Trinta dos 100 sujeitos que foram expostos ao ruído optaram por ajudar o homem, enquanto sessenta dos 100 sujeitos que não foram expostos ao ruído optaram por ajudar o homem. Os dados indicam que o comportamento altruísta é influenciado pelo ruído?
| Ajudou | Não ajudou | Total | |
|---|---|---|---|
| Barulho | 30 | 70 | 100 |
| Sem barulho | 60 | 40 | 100 |
| Total | 90 | 110 | 200 |
##
## Pearson's Chi-squared test
##
## data: dados
## X-squared = 18.182, df = 1, p-value = 2.008e-05##
## Pearson's Chi-squared test with Yates' continuity correction
##
## data: dados
## X-squared = 16.99, df = 1, p-value = 3.758e-05Exemplo 6.35 (Adaptado de (Sheskin 2011, 640), teste de independência) Um pesquisador deseja testar se existe relação entre a dimensão da personalidade de introversão-extroversão e afiliação política. Duzentas pessoas são recrutadas para participar do estudo. Todos os sujeitos passam por um teste de personalidade com base no qual cada sujeito é classificado como introvertido ou extrovertido. Pede-se para cada sujeito indicar se ele ou ela é um democrata ou um republicano conforme tabela a seguir. Os dados indicam que existe uma relação significativa entre a afiliação política e se alguém é introvertido ou não extrovertido?
| Democrata | Republicano | Total | |
|---|---|---|---|
| Introvertido | 30 | 70 | 100 |
| Extrovertido | 60 | 40 | 100 |
| Total | 90 | 110 | 200 |
##
## Pearson's Chi-squared test
##
## data: dados
## X-squared = 18.182, df = 1, p-value = 2.008e-05##
## Pearson's Chi-squared test with Yates' continuity correction
##
## data: dados
## X-squared = 16.99, df = 1, p-value = 3.758e-056.3.10.7 TESTE 13 - Teste exato de Fisher para tabelas \(2 \times 2\)
Este teste pode ser pensado como a versão exata (não assintótica) para o teste qui-quadrado de homogeneidade do TESTE 12 .
Hipótese avaliada (geral) Na(s) população(ões) representada(s) pela(s) amostra(s) em uma tabela de contingência, as frequências de células observadas são diferentes das frequências esperadas?
Hipóteses avaliadas (homogeneidade) As \(l\) amostras são ou não homogêneas com relação à proporção de observações em cada uma das \(c\) categorias? (ou) Se os dados forem homogêneos, a proporção de observações na \(j\)-ésima categoria será igual em todas as \(l\) populações?
Suposições
S1. Os dados avaliados representam uma amostra aleatória composta por \(n\) observações independentes.
S2. Os dados de frequência são categóricos para \(l \times c\) categorias mutuamente exclusivas.
S3. As somas das linhas e colunas (somas marginais) são predeterminadas/fixas.
Valor-p para tabelas \(2 \times 2\) Sob \(H_0: O_{ij}=E_{ij}\) para todas as células ou \(H_0: \pi_{ij}=(\pi_{i\cdot})(\pi_{\cdot j})\) para todas as \(l \times c\) células, \[\begin{equation} P = \frac{(a+c)!(b+d)!(a+b)!(c+d)!}{n!a!b!c!d!}, \tag{6.65} \end{equation}\] onde \(a\), \(b\), \(c\) e \(d\) são as quantidades conforme tabela a seguir.
| Coluna 1 | Coluna 2 | Total | |
|---|---|---|---|
| Linha 1 | \(a\) | \(b\) | a+b |
| Linha 2 | \(c\) | \(d\) | c+d |
| Total | \(a+c\) | \(b+d\) | n |
Exemplo 6.36 Pode-se resolver o Exemplo 6.34 através do teste exato de Fisher.
##
## Fisher's Exact Test for Count Data
##
## data: dados
## p-value = 3.305e-05
## alternative hypothesis: true odds ratio is not equal to 1
## 95 percent confidence interval:
## 0.1522789 0.5339334
## sample estimates:
## odds ratio
## 0.2876339Exercício 6.19 Faça os cálculos do Exemplo 6.36.
6.3.11 Paramétricos Multivariados
TESTE 14 - Análise de Variância (ANOVA) de um fator entre sujeitos
Hipótese avaliada Em um conjunto de \(k \ge 2\) grupos independentes, há pelo menos dois com médias distintas?
Suposições
S1. Cada amostra foi selecionada aleatoriamente da população que representa.
S2. A distribuição dos dados na população subjacente da qual cada uma das amostras é derivada é normal.
S3. (Homogeneidade de variâncias) A variância da população representada pelas \(k\) amostras são iguais entre si. (\(\sigma_1^2=\sigma_2^2=\cdots=\sigma_k^2\)).
Testes relacionados TESTE 21 - Teste de Kruskal-Wallis de um fator entre sujeitos
Estatística do teste Sob \(H_0: \mu_1=\mu_2=\cdots=\mu_k\), \[\begin{equation} F_{teste} = \frac{MQ_{EG}}{MQ_{IG}} \sim \mathcal{F}(gl_{EG},gl_{IG}), \tag{6.66} \end{equation}\]
onde \(MQ_{EG}\) é a média quadrática entre grupos dada por \[\begin{equation} MQ_{EG} = \frac{SQ_{EG}}{gl_{EG}}, \tag{6.67} \end{equation}\]
onde \(SQ_{EG}\) é a soma de quadrados entre grupos dada por \[\begin{equation} SQ_{EG} = \sum_{j=1}^k \left[ \frac{(\sum x_j)^2}{n_j} \right] - \frac{(\sum x_T)^2}{n}, \tag{6.68} \end{equation}\]
\(MQ_{IG}\) é a média quadrática intra grupos dada por \[\begin{equation} MQ_{IG} = \frac{SQ_{IG}}{gl_{IG}}, \tag{6.69} \end{equation}\]
onde \(SQ_{IG}\) é a soma de quadrados intra grupos dada por \[\begin{equation} SQ_{IG} = \sum_{j=1}^k \left[ \sum x_{j}^2 - \frac{(\sum x_j)^2}{n_j} \right], \tag{6.70} \end{equation}\]
\(gl_{EG}=k-1\) são os graus de liberdade entre grupos, \(gl_{IG}=n-k\) são os graus de liberdade intra grupos. Sabe-se também que onde \(SQ_{IG}\) é a soma de quadrados intra grupos dada por \[\begin{equation} SQ_{T} = SQ_{EG} + SQ_{IG} = \sum x_{T}^2 - \frac{(\sum x_T)^2}{n}. \tag{6.71} \end{equation}\]
Exemplo 6.37 (Adaptado de (Sheskin 2011, 886)) Um psicólogo realiza um estudo para determinar se o ruído pode ou não inibir o aprendizado. Cada um de 15 sujeitos é atribuído aleatoriamente a um dos três grupos. Cada sujeito tem 20 minutos para memorizar uma lista de 10 sílabas sem sentido, que ela diz que será testada no dia seguinte. Os cinco sujeitos atribuídos ao Grupo 1, a condição sem ruído, estudam a lista de sílabas sem sentido enquanto estão em uma sala silenciosa. Os cinco sujeitos designados para o Grupo 2, a condição de ruído moderado, estudam a lista de sílabas sem sentido enquanto ouvem música clássica. Os cinco sujeitos designados para o Grupo 3, a condição de ruído extremo, estudam a lista de sílabas sem sentido enquanto ouvem música rock. O número de sílabas sem sentido lembradas corretamente pelos 15 sujeitos segue: Grupo 1: 8,10,9,10,9; Grupo 2: 7,8,5,8,5; Grupo 3: 4,8,7,5,7. Os dados indicam que o ruído influenciou o desempenho dos sujeitos?
# dados
x <- c(8,10,9,10,9, 7,8,5,8,5, 4,8,7,5,7)
g <- as.factor(rep(1:3, each = 5))
(k <- length(unique(g))) # número de grupos## [1] 3
## g: 1
##
## Shapiro-Wilk normality test
##
## data: dd[x, ]
## W = 0.88104, p-value = 0.314
##
## ------------------------------------------------------------------------------------------------------
## g: 2
##
## Shapiro-Wilk normality test
##
## data: dd[x, ]
## W = 0.80299, p-value = 0.08569
##
## ------------------------------------------------------------------------------------------------------
## g: 3
##
## Shapiro-Wilk normality test
##
## data: dd[x, ]
## W = 0.91367, p-value = 0.4899## Levene's Test for Homogeneity of Variance (center = median)
## Df F value Pr(>F)
## group 2 0.6667 0.5314
## 12## g: 1
## [1] 46
## ------------------------------------------------------------------------------------------------------
## g: 2
## [1] 33
## ------------------------------------------------------------------------------------------------------
## g: 3
## [1] 31## g: 1
## [1] 9.2
## ------------------------------------------------------------------------------------------------------
## g: 2
## [1] 6.6
## ------------------------------------------------------------------------------------------------------
## g: 3
## [1] 6.2## g: 1
## [1] 426
## ------------------------------------------------------------------------------------------------------
## g: 2
## [1] 227
## ------------------------------------------------------------------------------------------------------
## g: 3
## [1] 203## g: 1
## [1] 5
## ------------------------------------------------------------------------------------------------------
## g: 2
## [1] 5
## ------------------------------------------------------------------------------------------------------
## g: 3
## [1] 5## [1] 110## [1] 856## [1] 15## [1] 49.33333## [1] 26.53333## [1] 22.8## [1] 22.8## [1] 2## [1] 12## [1] 13.26667## [1] 1.9## [1] 6.982456## [1] 0.009007219## Df Sum Sq Mean Sq F value Pr(>F)
## g 2 26.53 13.27 6.982 0.00974 **
## Residuals 12 22.80 1.90
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## Analysis of Variance Table
##
## Response: x
## Df Sum Sq Mean Sq F value Pr(>F)
## g 2 26.533 13.267 6.9825 0.009745 **
## Residuals 12 22.800 1.900
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Anova Table (Type II tests)
##
## Response: x
## Sum Sq Df F value Pr(>F)
## g 26.533 2 6.9825 0.009745 **
## Residuals 22.800 12
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1##
## Call:
## lm(formula = x ~ g)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.2 -1.2 0.4 0.8 1.8
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 9.2000 0.6164 14.924 4.12e-09 ***
## g2 -2.6000 0.8718 -2.982 0.01143 *
## g3 -3.0000 0.8718 -3.441 0.00488 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.378 on 12 degrees of freedom
## Multiple R-squared: 0.5378, Adjusted R-squared: 0.4608
## F-statistic: 6.982 on 2 and 12 DF, p-value: 0.009745## Tukey multiple comparisons of means
## 95% family-wise confidence level
##
## Fit: aov(formula = x ~ g)
##
## $g
## diff lwr upr p adj
## 2-1 -2.6 -4.92579 -0.2742104 0.0286083
## 3-1 -3.0 -5.32579 -0.6742104 0.0125541
## 3-2 -0.4 -2.72579 1.9257896 0.8914526## # A tibble: 3 × 9
## term group1 group2 null.value estimate conf.low conf.high p.adj p.adj.signif
## * <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 g 1 2 0 -2.6 -4.93 -0.274 0.0286 *
## 2 g 1 3 0 -3 -5.33 -0.674 0.0126 *
## 3 g 2 3 0 -0.400 -2.73 1.93 0.891 nsExercício 6.20 (Adaptado de (DeGroot and Schervish 2012, 754)) Moore e McCabe (1999) descrevem dados coletados em Consumer Reports (junho de 1986, pp. 364-67). Os dados incluem (entre outras coisas) calorias conteúdo de 63 marcas de salsichas de cachorros-quentes conforme tabela a seguir. A salsichas vêm em quatro variedades: carne bovina, carne (?), aves e especialidades. É interessante saber se, e em que medida, as diferentes variedades diferem em seus conteúdos calóricos. Realize o procedimento de análise de variância e post hoc, indicando se há diferença significativa entre os grupos.
Carne bovina 186, 181, 176, 149, 184, 190, 158, 139, 175, 148, 152, 111, 141, 153, 190, 157, 131, 149, 135, 132
Carne 173, 191, 182, 190, 172, 147, 146, 139, 175, 136, 179, 153,107, 195, 135, 140, 138
Aves 129, 132, 102, 106, 94, 102, 87, 99, 107, 113, 135, 142, 86, 143, 152, 146, 144
Especialidades 155, 170, 114, 191, 162, 146, 140, 187, 180
# Dica
g <- as.factor(rep(1:4, times = c(20,17,17,9)))
x <- c(186,181,176,149,184,190,158,139,175,148,152,111,141,153,190,157,131,149,135,132,
173,191,182,190,172,147,146,139,175,136,179,153,107,195,135,140,138,
129,132,102,106,94,102,87,99,107,113,135,142,86,143,152,146,144,
155,170,114,191,162,146,140,187,180)
boxplot(x ~ g)
6.3.12 Não Paramétricos Univariados
TESTE 15 - Teste dos postos sinalizados de Wilcoxon para uma amostra
Hipótese avaliada Uma amostra de \(n\) sujeitos (ou objetos) vem de uma população em que a mediana \(\theta\) é igual a um valor especificado?
Suposições
S1. Cada amostra foi selecionada aleatoriamente da população que representa.
S2. As pontuações originais obtidas para cada um dos sujeitos/objetos são quantitativas.
S3. A distribuição da população subjacente é simétrica.
Testes relacionados TESTE 1 - Teste \(z\) para média de uma amostra TESTE 2 - Teste \(t\) para média de uma amostra
Para testar a simetria foi considerada a função symmetry_test do pacote symmetry. Segundo (Milošević and Obradović 2018, 4), entre os testes originalmente destinados a testar simetria em torno de uma média desconhecida, o mais famoso é o teste clássico \(\sqrt{b_1}\), baseado no coeficiente de assimetria da amostra, com estatística de teste \(\sqrt{b_1} = m_3/s^3\) onde \(m_3\) é o terceiro momento central da amostra conforme numerador da Eq. (2.40) e \(s\) é o desvio padrão amostral conforme Eq. (2.35).
# dados
set.seed(456); z <- rnorm(100) # N(0,1)
# verificando suposição S3 (simetria)
library(symmetry)
set.seed(111); symmetry_test(z, 'B1') # √b1##
## Symmetry test
## Null hypothesis: Data is symmetric
##
## data: z
## B1 = -0.00024191, B = 1000, p-value = 0.998
## sample estimates:
## mu
## 0.1205748##
## Wilcoxon signed rank test with continuity correction
##
## data: z
## V = 2851, p-value = 0.2631
## alternative hypothesis: true location is not equal to 0##
## Wilcoxon signed rank test with continuity correction
##
## data: z
## V = 563, p-value = 1.538e-11
## alternative hypothesis: true location is not equal to 1TESTE 16 - Teste de aderência de Shapiro-Wilk para uma amostra
Hipótese avaliada Os dados têm distribuição normal?
Suposições
S1. Cada amostra foi selecionada aleatoriamente da população que representa.
S2. A escala de mensuração é quantitativa.
##
## Shapiro-Wilk normality test
##
## data: z
## W = 0.98521, p-value = 0.3287##
## Shapiro-Wilk normality test
##
## data: u
## W = 0.95686, p-value = 0.0024156.3.13 Não Paramétricos Bivariados
TESTE 17 - Teste de Kolmogorov-Smirnov para duas amostras independentes
Hipótese avaliada Duas amostras independentes representam duas populações distintas?
Suposições
S1. Cada amostra foi selecionada aleatoriamente da população que representa.
S2. A escala de mensuração é pelo menos ordinal.
##
## Exact two-sample Kolmogorov-Smirnov test
##
## data: x and y
## D = 0.52, p-value = 3.885e-05
## alternative hypothesis: two-sided##
## Exact two-sample Kolmogorov-Smirnov test
##
## data: x and z
## D = 0.54667, p-value = 1.178e-05
## alternative hypothesis: two-sided##
## Exact two-sample Kolmogorov-Smirnov test
##
## data: y and z
## D = 0.16667, p-value = 0.808
## alternative hypothesis: two-sidedTESTE 18 - Teste dos postos de Mann-Whitney para amostras independentes
Hipótese avaliada Duas amostras independentes representam duas populações com medianas diferentes?
Suposições
S1. Cada amostra foi selecionada aleatoriamente da população que representa.
S2. As duas amostras são independentes entre si.
S3. Os dados são ordinais ou quantitativos.
S4. As distribuições de onde as amostras foram retiradas possuem mesma forma.
Testes relacionados TESTE 7 - Teste \(z\) para médias de duas amostras independentes TESTE 8 - Teste \(t\) para médias de duas amostras independentes
Exemplo 6.38 (Adaptado de (Sheskin 2011, 532)) Para avaliar a eficácia de um novo medicamento antidepressivo, dez pacientes com depressão clínica são aleatoriamente designados para um dos dois grupos. Cinco pacientes são atribuídos ao Grupo 1, onde é administrado o antidepressivo por um período de seis meses. Os outros cinco pacientes são atribuídos ao Grupo 2, que recebe um placebo durante o mesmo período de seis meses. Suponha que, antes de introduzir os tratamentos experimentais, o experimentador confirmou que o nível de depressão nos dois grupos era igual. Após seis meses, todos os dez sujeitos são avaliados por um psiquiatra (que é cego em relação à condição experimental do sujeito) quanto ao nível de depressão. As classificações de depressão do psiquiatra para os cinco sujeitos em cada grupo seguem (quanto mais alta a classificação, mais deprimido é o sujeito): Grupo 1: 11, 1,0, 2, 0; Grupo 2: 11, 11, 5, 8, 4. Os dados indicam que o antidepressivo é eficaz?
\[\left\{ \begin{array}{l} H_0: \theta_1 \ge \theta_2 \equiv \theta_1 - \theta_2 \ge 0 \; \text{(tratamento igual ou menos eficaz que o placebo)} \\ H_1: \theta_1 < \theta_2 \equiv \theta_1 - \theta_2 < 0 \; \text{(tratamento mais eficaz que o placebo)} \\ \end{array} \right. \]
## [1] 1## [1] 8##
## Exact two-sample Kolmogorov-Smirnov test
##
## data: x and y
## D = 0.8, p-value = 0.07937
## alternative hypothesis: two-sided##
## Wilcoxon rank sum test with continuity correction
##
## data: x and y
## W = 4, p-value = 0.04484
## alternative hypothesis: true location shift is less than 0TESTE 19 - Teste dos postos de Wilcoxon para amostras dependentes/pareadas
Hipótese avaliada Duas amostras dependentes representam duas populações distintas?
Suposições
S1. Cada amostra foi selecionada aleatoriamente da população que representa.
S2. As pontuações originais obtidas para cada um dos sujeitos/objetos são quantitativas.
S3. A distribuição dos escores de diferença nas populações representadas pelas duas amostras é simétrica em relação à mediana da população de escores de diferença.
Testes relacionados TESTE 9 - Teste \(t\) para médias de duas amostras dependentes/pareadas.
Assim como no teste dos postos sinalizados de Wilcoxon para uma amostra (TESTE 16), para testar a simetria foi considerada a estatística \(\sqrt{b_1}\) da função symmetry::symmetry_test.
# dados
x <- c(1.83, 0.50, 1.62, 2.48, 1.68, 1.88, 1.55, 3.06, 1.30)
y <- c(0.878, 0.647, 0.598, 2.05, 1.06, 1.29, 1.06, 3.14, 1.29)
median(x-y)## [1] 0.49# verificando suposição S3 (simetria da diferença em relação à mediana)
set.seed(111); symmetry::symmetry_test(x-y, 'B1', mu = median(x-y)) # √b1##
## Symmetry test
## Null hypothesis: Data is symmetric around 0.49
##
## data: x - y
## B1 = -0.066026, B = 1000, p-value = 0.874# teste de Wilcoxon para amostras pareadas
wilcox.test(x, y, paired = TRUE, alternative = 'greater')##
## Wilcoxon signed rank exact test
##
## data: x and y
## V = 40, p-value = 0.01953
## alternative hypothesis: true location shift is greater than 0TESTE 20 - Teste de McNemar para amostras dependentes/pareadas
Hipótese avaliada Duas amostras dependentes representam duas populações distintas?
Suposições
S1. Cada amostra foi selecionada aleatoriamente da população que representa.
S2. As variáveis são binárias e categóricas (ordinais ou nominais).
S3. Cada um dos \(n\) sujeitos (ou \(n\) pares de sujeitos combinados) contribui com duas pontuações na variável dependente.
Estatística do teste Sob \(H_0:\pi_{12}=\pi_{21}\), \[\begin{equation} \chi_{teste}^2 = \frac{(n_{12}-n_{21})^2}{n_{12}+n_{21}} \sim \chi^2(1) \tag{6.72} \end{equation}\] onde \(n_{12}\) indica o número de elementos da linha 1, coluna 2 da tabela e \(n_{21}\) indica o número de elementos da linha 2, coluna e \(\chi^2(1)\) indica a distribuição qui-quadrado com 1 grau de liberdade.
Estatística do teste com correção de continuidade Sob \(H_0:\pi_{12}=\pi_{21}\), \[\begin{equation} \chi_{teste}^2 = \frac{(|n_{12}-n_{21}|-1)^2}{n_{12}+n_{21}} \sim \chi^2(1) \tag{6.73} \end{equation}\]
Valor-p Sob \(H_0: \pi_{12}=\pi_{21}\), \[\begin{equation} \text{Valor-p} = Pr(\chi^2 \ge \chi_{teste}^2). \tag{6.74} \end{equation}\]
Exemplo 6.39 (Exemplo da documentação de mcnemar.test) A aprovação do desempenho do Presidente no cargo foi realizado em duas pesquisas, com um mês de intervalo, para uma amostra aleatória de 1.600 americanos em idade de votar. Os dados indicam uma mudança de percepção em relação às duas pesquisas?
# dados
dat <- matrix(c(794, 86, 150, 570), nrow = 2,
dimnames = list('1ª pesquisa' = c('Aprova', 'Desaprova'),
' 2ª pesquisa' = c('Aprova', 'Desaprova')))
dat## 2ª pesquisa
## 1ª pesquisa Aprova Desaprova
## Aprova 794 150
## Desaprova 86 570## [1] 17.35593## [1] 3.099293e-05##
## McNemar's Chi-squared test
##
## data: dat
## McNemar's chi-squared = 17.356, df = 1, p-value = 3.099e-05# usando a estatística do teste com correção
(qui.c <- (abs(dat[1,2]-dat[2,1])-1)^2/(dat[1,2]+dat[2,1]))## [1] 16.8178## [1] 4.114562e-05##
## McNemar's Chi-squared test with continuity correction
##
## data: dat
## McNemar's chi-squared = 16.818, df = 1, p-value = 4.115e-05Exercício 6.21 (Adaptado de (Sheskin 2011, 837)) Um pesquisador conduz um estudo para investigar se uma série semanal de televisão altamente crítica quanto ao uso de animais em pesquisas médicas influencia a opinião pública. Cem sujeitos selecionados aleatoriamente são avaliados por um teste para determinar sua atitude em relação ao uso de animais em pesquisas médicas. Com base em suas respostas, os sujeitos são então categorizados como pró-pesquisa com animais ou anti-pesquisa com animais. Após o pré-teste, todos os sujeitos são orientados a assistir à série de televisão (com duração de dois meses). Na conclusão da série, a atitude de cada sujeito em relação à pesquisa animal é reavaliada. Os resultados do estudo estão resumidos na tabela a seguir. Os dados indicam que uma mudança de atitude em relação à pesquisa com animais ocorreu depois que os participantes assistiram à série de televisão?
Resolva utilizando as estatísticas com e sem correção de continuidade, realizando os cálculos e também aplicando a função mcnemar.test.
| Pós-teste | |||
|---|---|---|---|
| Pré-teste | Anti | Pró | Total |
| Anti | 10 | 13 | 23 |
| Pró | 41 | 36 | 77 |
| Total | 51 | 49 | 100 |
# dados
dados <- matrix(c(10,41,13,36), nrow = 2,
dimnames = list('Pré-teste' = c('Anti', 'Pró'),
'Pós-teste' = c('Anti', 'Pró')))
dados## Pós-teste
## Pré-teste Anti Pró
## Anti 10 13
## Pró 41 36##
## McNemar's Chi-squared test with continuity correction
##
## data: dados
## McNemar's chi-squared = 13.5, df = 1, p-value = 0.00023866.3.14 Não Paramétricos Multivariados
TESTE 21 - Teste de Kruskal-Wallis de um fator entre sujeitos
Hipótese avaliada Em um conjunto de \(k \ge 2\) grupos independentes, há pelo menos dois com medianas distintas?
Suposições
S1. Cada amostra foi selecionada aleatoriamente da população que representa.
S2. As \(k\) amostras são independentes umas das outras.
S3. A variável dependente (que é subsequentemente classificada) é uma variável aleatória contínua.
S4. As distribuições subjacentes das quais as amostras são derivadas possuem a mesma forma, não obrigatoriamente normais.
Testes relacionados TESTE 14 - Análise de Variância (ANOVA) de um fator entre sujeitos TESTE X - Teste de Dunn (ver https://rcompanion.org/rcompanion/d_06.html)
Exemplo 6.40 Pode-se resolver o Exemplo 6.37 através do teste de Kruskal-Wallis.
# dados
x <- c(8,10,9,10,9, 7,8,5,8,5, 4,8,7,5,7)
g <- as.factor(rep(1:3, each = 5))
(k <- length(unique(g))) # número de grupos## [1] 3
# validando suposição S4 via TESTE 21 - teste K-S para duas amostras independentes
ks.test(x[1:5], x[6:10])##
## Exact two-sample Kolmogorov-Smirnov test
##
## data: x[1:5] and x[6:10]
## D = 0.8, p-value = 0.04762
## alternative hypothesis: two-sided##
## Exact two-sample Kolmogorov-Smirnov test
##
## data: x[1:5] and x[11:15]
## D = 0.8, p-value = 0.07937
## alternative hypothesis: two-sided##
## Exact two-sample Kolmogorov-Smirnov test
##
## data: x[6:10] and x[11:15]
## D = 0.2, p-value = 1
## alternative hypothesis: two-sided##
## Kruskal-Wallis rank sum test
##
## data: x and g
## Kruskal-Wallis chi-squared = 8.7474, df = 2, p-value = 0.0126## Df Sum Sq Mean Sq F value Pr(>F)
## g 2 26.53 13.27 6.982 0.00974 **
## Residuals 12 22.80 1.90
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Comparison Z P.unadj P.adj
## 1 1 - 2 2.3402675 0.019269934 0.02890490
## 2 1 - 3 2.7363127 0.006213195 0.01863958
## 3 2 - 3 0.3960453 0.692071636 0.69207164Exercício 6.22 Refaça o exercício 6.20 aplicando o teste de Kruskal-Wallis.

Referências
“The value for which P=.05, or 1 in 20, is 1.96 or nearly 2; it is convenient to take this point as a limit in judging whether a deviation is to be considered significant or not. Deviations exceeding twice the standard deviation are thus formally regarded as significant.” Ronald Aylmer Fisher na primeira edição do seu livro Statistical Methods For Research Workers, de 1925.↩︎
Ainda que (Ronald A. Fisher 1936) tenha posto dúvida sobre o trabalho de Mendel ao criar a noção do Paradoxo Mendeliano, ou ‘bom demais para ser verdade’. Tal consideração tem bases eugenistas e incondicionalistas, calcada sob uma ótica ultrapassada assumida por Fisher e seus mentores, Karl Pearson e Francis Galton e já desmentida por acadêmicos como (Novitski 2004) e (Hartl and Fairbanks 2007).↩︎
A análise post hoc é aplicada quando uma hipótese de múltiplas igualdades é rejeitada, admitindo-se que ‘há pelo menos dois grupos distintos’. Neste caso, fica a pergunta: quais grupos são distintos e em que grau? A terminologia é baseada na expressão latina que significa ‘depois disto’.↩︎