Capítulo 10
Solução. 10.8
pib <- read.table('https://filipezabala.com/data/pib.txt', head = T, sep = '\t')
# PASSO 1 Padronizar os dados
pib.s = scale(pib[,-c(1:2)])
rownames(pib.s) = pib$Country
# PASSO 2 Calcular as (dis)similaridades
dpib.s = dist(pib.s, method = 'minkowski', p = 4)
# PASSO 3 Usar a função de ligação para agrupar os objetos na árvore a partir das informações de distância obtidas na passo 1.
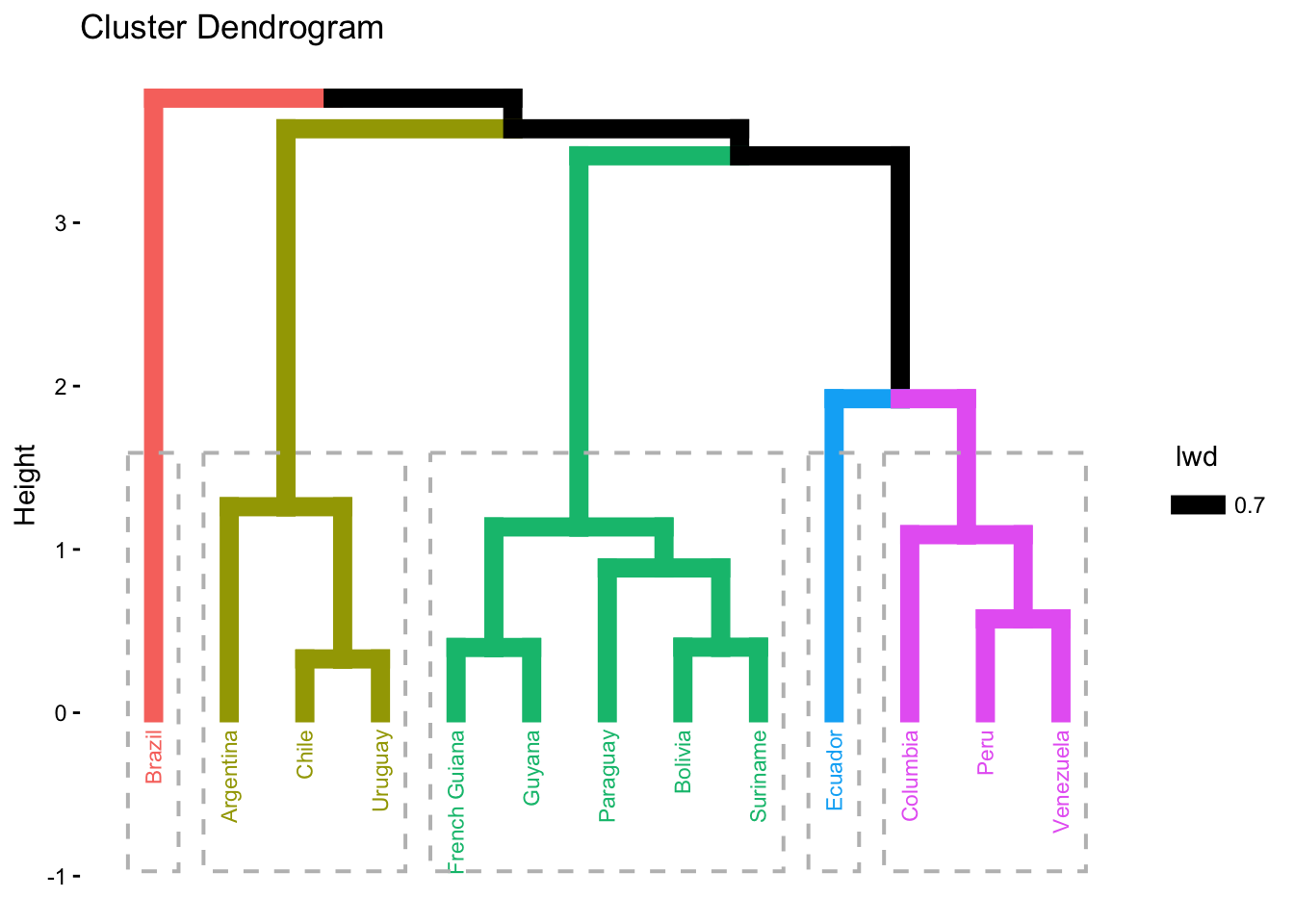
hc = hclust(dpib.s)
# PASSO 4 Apresentar o gráfico da árvore hierárquica em grupos (dendograma), criando uma partição dos dados.
# raiz
plot(hc)
# nutela
library(factoextra)
fviz_dend(hc, k = 5, # número de grupos desejado
cex = 0.6, # tamanho do texto/rótulo (label)
rect = TRUE # adiciona retângulos ao redor dos grupos
)
# k-means
iris2 <- scale(iris[-5])
S <- rowSums(iris2)
k <- 2
zab <- k*(S - min(S))/(1.01*max(S)-min(S)) + 1 # baseada em Hartigan (1975)
(g <- floor(zab)) # grupos## [1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2
## [52] 2 2 1 2 1 2 1 2 1 1 2 1 2 1 2 1 1 1 1 2 1 1 1 2 2 2 2 2 1 1 1 1 2 1 2 2 1 1 1 1 2 1 1 1 1 1 1 1 1 2 2
## [103] 2 2 2 2 1 2 2 2 2 2 2 1 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2## g
## 1 2
## 83 67## INDICES: 1
## Sepal.Length Sepal.Width Petal.Length Petal.Width
## -0.70707156 0.03984126 -0.68805740 -0.70250780
## ---------------------------------------------------------------------------------
## INDICES: 2
## Sepal.Length Sepal.Width Petal.Length Petal.Width
## 0.87592447 -0.04935559 0.85236961 0.87027086## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :-1.86378 Min. :-2.4258 Min. :-1.5623 Min. :-1.4422
## 1st Qu.:-0.89767 1st Qu.:-0.5904 1st Qu.:-1.2225 1st Qu.:-1.1799
## Median :-0.05233 Median :-0.1315 Median : 0.3354 Median : 0.1321
## Mean : 0.00000 Mean : 0.0000 Mean : 0.0000 Mean : 0.0000
## 3rd Qu.: 0.67225 3rd Qu.: 0.5567 3rd Qu.: 0.7602 3rd Qu.: 0.7880
## Max. : 2.48370 Max. : 3.0805 Max. : 1.7799 Max. : 1.7064