6.4 MANOVA (Multivariate ANalysis Of VAriance)
MANOVA é a versão multivariada da ANOVA (ANalysis Of VAriance) e uma extensão do teste de Hotelling para mais de dois grupos. A hipótese nula considerada é \(H_0: \boldsymbol{\mu}_1 = \boldsymbol{\mu}_2 = \ldots = \boldsymbol{\mu}_k\), onde \(\boldsymbol{\mu}_i\) tem dimensão \(p \times 1\), \(i \in \left\{1,2, \ldots, k\right\}\). Possui quatro estatísticas de teste usuais, apresentadas a seguir conforme (Tattar et al. 2016).
Seja \(\boldsymbol{y}_{ij}\) a \(j\)-ésima observação da \(i\)-ésima população, \(j \in \left\{ 1,2, \ldots, n \right\}\), \(i \in \left\{1,2, \ldots, k\right\}\). Assume-se \(\boldsymbol{y}_{ij} \sim N(\boldsymbol{\mu}_{i},\Sigma)\). O modelo especificado para as observações é \[ \boldsymbol{y}_{ij} = \boldsymbol{\mu}_i + \boldsymbol{\alpha}_i + \boldsymbol{\varepsilon}_{ij} = \boldsymbol{\mu}_i + \boldsymbol{\varepsilon}_{ij} \] Como consequência da suposição de normalidade para \(\boldsymbol{y}_{ij}\), \(\varepsilon \sim N(\boldsymbol{\mu},\Sigma)\), e \(\boldsymbol{\alpha}_i\) é o efeito médio da \(i\)-ésima população. As matrizes de somas de quadrados ‘intra’ (erro experimental) e ‘entre’ (tratamentos) são denotadas respectivamente por \(W\) (\(W\)ithin/intra) e \(B\) (\(B\)etween/entre) e definidas a seguir.
\[\begin{equation} W = n \sum_{i=1}^{k} (\bar{\boldsymbol{y}}_{i\cdot} - \bar{\boldsymbol{y}}_{\cdot\cdot}) (\bar{\boldsymbol{y}}_{i\cdot} - \bar{\boldsymbol{y}}_{\cdot\cdot})^{T} \tag{6.5} \end{equation}\]
\[\begin{equation} B = \sum_{i=1}^{k} \sum_{j=1}^{n} (\bar{\boldsymbol{y}}_{ij} - \bar{\boldsymbol{y}}_{i\cdot}) (\bar{\boldsymbol{y}}_{ij} - \bar{\boldsymbol{y}}_{i\cdot})^{T} \tag{6.6} \end{equation}\]
6.4.1 Estatísticas de teste
Wilk
O lambda (\(\Lambda\)) de Wilk é o determinante da matriz \(W\) dividido pelo determinante de \(W+B\). Isso informa o quanto a matriz de variância intra grupo representa da variância total. Se existe um efeito indicado pelos dados, \(W\) deve ter uma variância pequena em relação à variância total \(B+W\). Ao contrário da estatística \(\mathcal{F}\) em uma ANOVA, rejeita-se a hipótese nula quando o Lambda de Wilk é pequeno.
\[\begin{equation} \Lambda = \frac{|W|}{|W+B|} = \prod_{i=1}^{s} \frac{1}{1+\lambda_i} \tag{6.7} \end{equation}\]
Hotelling-Lawley
A estatística de teste de Hotelling-Lawley calcula o traço da matriz \(BW^{-1}\). Se \(B\) é grande em comparação a \(W\), o traço será grande (ao contrário do Lambda de Wilk) então rejeitamos quando o traço é significativamente grande.
\[\begin{equation} U^{(s)} = tr(BW^{-1}) \tag{6.8} \end{equation}\]
Pillai(-Bartlett)
Assim como na estatística de Hotelling-Lawley, a estatística de Pillai(-Bartlett) calcula o traço de uma matriz, no caso \(B(B+W)^{-1}\). Este é o análogo matricial da razão entre a soma dos quadrados da hipótese e a soma total dos quadrados. Se \(B\) for grande em comparação à matriz de variância total \(B+W\), o traço de Pillai(-Bartlett) será grande e tende-se a rejeitar \(H_0\).
\[\begin{equation} V^{(s)} = tr( B(B+W)^{-1} ) = \sum_{i=1}^{s} \frac{\lambda_i}{1+\lambda_i} \tag{6.9} \end{equation}\]
Roy
Assim como nos traços de Hotelling-Lawley e Pillai(-Bartlett), a raiz máxima de Roy é o maior autovalor de \(BW^{-1}\), e será grande se \(B\) for grande em comparação a \(W\). Como utiliza-se apenas o maior autovalor (\(\lambda_1\)), a estatística de Roy frequentemente superestima o efeito. Portanto, se nenhuma das outras estatísticas de teste for significativa e apenas a de Roy indicar significância, provavelmente estamos diante de um falso positivo.
\[\begin{equation} \theta = \prod_{i=1}^{s} \frac{\lambda_1}{1+\lambda_1} \tag{6.10} \end{equation}\]
Exemplo 6.8 MANOVA aplicada em iris, adaptado de https://rpubs.com/Klarisa04/894145.
library(ggplot2)
library(gridExtra)
# gráficos
box_sl <- ggplot(iris, aes(x = Species, y = Sepal.Length, fill = Species)) +
geom_boxplot() +
theme(legend.position = "top")
box_sw <- ggplot(iris, aes(x = Species, y = Sepal.Width, fill = Species)) +
geom_boxplot() +
theme(legend.position = "top")
box_pl <- ggplot(iris, aes(x = Species, y = Petal.Length, fill = Species)) +
geom_boxplot() +
theme(legend.position = "top")
box_pw <- ggplot(iris, aes(x = Species, y = Petal.Width, fill = Species)) +
geom_boxplot() +
theme(legend.position = "top")
grid.arrange(box_sl, box_sw, box_pl, box_pw, ncol = 2, nrow = 2)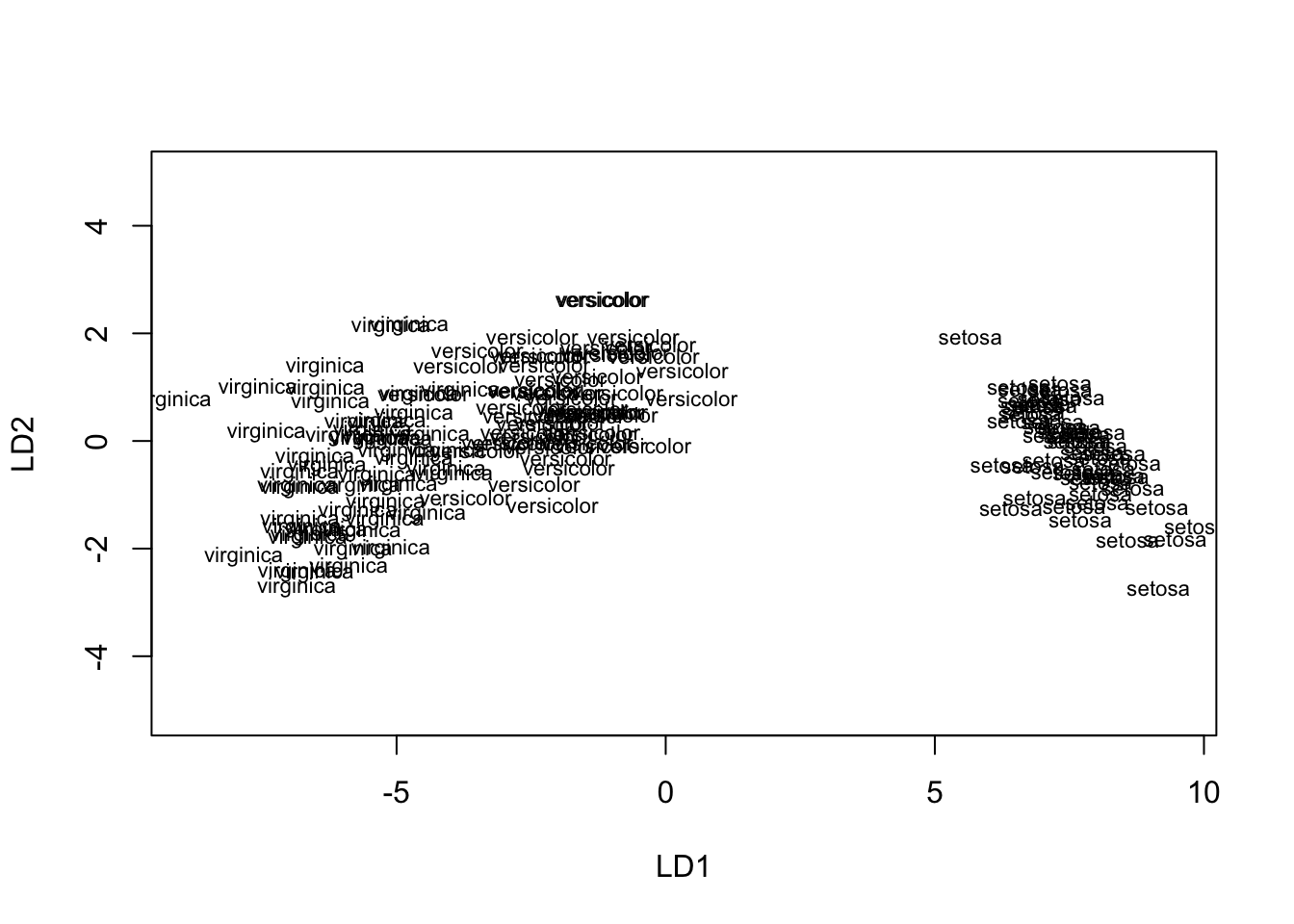
Hipóteses: os vetores média 4-variados de setosa, versicolor e virginica podem ser considerados iguais?
\(H_0: \boldsymbol{\mu}_{\text{setosa}} = \boldsymbol{\mu}_{\text{versicolor}} = \boldsymbol{\mu}_{\text{virginica}}\)
# dados
Y <- as.matrix(iris[,-5])
g <- iris[,5]
# MANOVA
m <- manova(Y ~ g)
summary(m, test = 'Wilks') ## Df Wilks approx F num Df den Df Pr(>F)
## g 2 0.023439 199.15 8 288 < 2.2e-16 ***
## Residuals 147
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Df Hotelling-Lawley approx F num Df den Df Pr(>F)
## g 2 32.477 580.53 8 286 < 2.2e-16 ***
## Residuals 147
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Df Pillai approx F num Df den Df Pr(>F)
## g 2 1.1919 53.466 8 290 < 2.2e-16 ***
## Residuals 147
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Df Roy approx F num Df den Df Pr(>F)
## g 2 32.192 1167 4 145 < 2.2e-16 ***
## Residuals 147
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1O teste post-hoc pode ser relizado via Análise Discriminante, conforme detalhado na Seção 9.10. Primeiro testamos a homogeneidade das matrizes de covariância entre os grupos.
##
## Box's M-test for Homogeneity of Covariance Matrices
##
## data: iris[, -5]
## Chi-Sq (approx.) = 140.94, df = 20, p-value < 2.2e-16A diferença significativa (p-value < 2.2e-16) sugere que é mais interessante considerar a QDA, que não faz a suposição de igualdade de matrizes de variâncias e covariâncias.
Exemplo 6.9 Adaptado de https://www.youtube.com/watch?v=iEBBcckQL0I.
library(mvtnorm)
# dados simulados
m <- c(10,20)
S <- matrix(c(25,10,10,25), ncol = 2)
set.seed(1)
data <- rmvnorm(n = 150, mean = m, sigma = S)
grupo <- c(rep(1,50) ,rep(0,50), rep(2,50))
data <- cbind(data, grupo)
colnames(data) <- c('cintura', 'coxa', 'grupo')
data <- as.data.frame(data)
data$grupo <- as.factor(data$grupo)
Y <- as.matrix(cbind(data$cintura, data$coxa))
g <- as.vector(data$grupo)
# MANOVA
m <- manova(Y ~ g)
summary(m, test = 'Wilks') ## Df Wilks approx F num Df den Df Pr(>F)
## g 2 0.9821 0.6622 4 292 0.6187
## Residuals 147## Df Hotelling-Lawley approx F num Df den Df Pr(>F)
## g 2 0.018183 0.65915 4 290 0.6209
## Residuals 147## Df Pillai approx F num Df den Df Pr(>F)
## g 2 0.01794 0.66524 4 294 0.6166
## Residuals 147## Df Roy approx F num Df den Df Pr(>F)
## g 2 0.015501 1.1393 2 147 0.3228
## Residuals 147